거의 모든 테이블 형식 데이터 세트를 빠르게 처리하는 방법
새 데이터 세트에 대한 좋은 느낌을 얻는 것이 항상 쉬운 일이 아니며 시간이 걸립니다. 그러나 훌륭하고 광범위한 탐색적 데이터 분석(EDA)은 데이터 세트를 이해하고, 데이터가 어떻게 연결되어 있는지, 데이터 세트를 적절하게 처리하기 위해 수행해야 하는 작업에 대한 느낌을 얻는 데 많은 도움이 될 수 있습니다.
이 기사에서는 여러 가지 유용한 EDA 루틴을 다룰 것입니다. 그러나 내용을 짧고 간결하게 유지하기 위해 항상 더 깊이 파고들거나 모든 의미를 설명하지 못할 수도 있습니다. 그러나 실제로 데이터 세트를 완전히 이해하기 위해 적절한 EDA에 충분한 시간을 투자하는 것은 훌륭한 데이터 과학 프로젝트의 핵심 부분입니다. 일반적으로 데이터 준비 및 탐색에 80%의 시간을 할애하고 실제 기계 학습 모델링에 20%만 할애할 것입니다.
구조, 품질 및 내용 조사
전반적으로 EDA 접근 방식은 매우 반복적입니다. 조사가 끝나면 모든 것을 다시 한 번 수행해야 하는 무언가를 발견할 수 있습니다. 정상입니다! 그러나 적어도 약간의 구조를 부과하기 위해 귀하의 조사를 위해 다음 구조를 제안합니다.
- 구조 조사(Structure investigation) : 데이터 세트의 일반적인 모양과 피처의 데이터 유형을 탐색합니다.
- 품질 조사(Quality investigation) : 중복, 누락된 값 및 원치 않는 항목과 관련하여 데이터 세트의 일반적인 품질에 대한 느낌을 얻습니다.
- 콘텐츠 조사(Content investigation) : 데이터 세트의 구조와 품질이 이해되면 기능 값에 대해 더 심층적인 탐색을 수행하고 다양한 기능이 서로 어떻게 관련되어 있는지 확인할 수 있습니다.
이번 내용은 2에 이어서 진행됩니다.
3.2. 기능 패턴
목록의 다음 단계는 기능별 패턴을 조사하는 것입니다. 이 부분의 목표는 두 가지입니다.
- 일부 항목을 삭제하거나 수정해야 하는지 여부를 결정하는 데 도움이 되는 기능 내에서 특정 패턴을 식별할 수 있습니까?
- 데이터 세트를 더 잘 이해하는 데 도움이 되는 기능 간의 특정 관계를 식별할 수 있습니까?
이 두 가지 질문에 대해 알아보기 전에 '무작위로 선택된' 몇 가지 기능을 자세히 살펴보겠습니다.
df_X[["Location_Northing_OSGR",
"1st_Road_Number",
"Journey_Purpose_of_Driver",
"Pedestrian_Crossing-Physical_Facilities"]].plot(
lw=0, marker=".", subplots=True, layout=(-1, 2),
markersize=0.1, figsize=(15, 6));
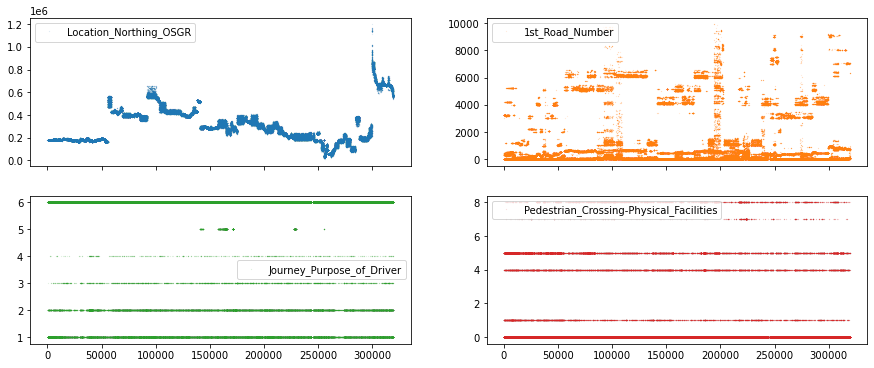
맨 위 행에는 연속적인 값(예: 숫자 라인에서 임의의 숫자)이 있는 기능이 표시되고
맨 아래 행에는 이산 값(예: 1, 2, 3이지만 2.34는 아님)이 있는 특성이 있습니다.
특정 패턴에 대한 기능을 탐색할 수 있는 방법은 여러 가지가 있지만 고유 기능이 25개 미만인 기능을 이산 또는 순서 기능으로,
다른 기능을 연속 기능으로 처리하도록 결정하여 옵션을 단순화하겠습니다.
# Creates mask to identify numerical features with at least 25 unique features
cols_continuous = df_X.select_dtypes(include="number").nunique() >= 253.2.1. 연속 기능
이제 연속적인 기능을 선택할 수 있는 방법이 있으므로
seaborn을 사용 pairplot하여 이러한 기능 간의 관계를 시각화해 보겠습니다.
참고 로 seaborn의 pairplot 루틴은 모든 서브플롯을 생성하는 데 오랜 시간이 걸릴 수 있습니다.
따라서 한 번에 ~10개 이상의 기능에 사용하지 않는 것이 좋습니다.
우리의 경우 기능이 11개뿐이라는 점을 감안할 때 pairplot을 진행할 수 있습니다.
그렇지 않으면 다음과 같은 것을 사용 df_continuous.iloc[:, :5]하면 플롯할 기능의 수를 줄이는 데 도움이 될 수 있습니다.
# Create a new dataframe which only contains the continuous features
df_continuous = df_X[cols_continuous[cols_continuous].index]
df_continuous.shape
>>> (317665, 11)
import seaborn as sns
sns.pairplot(df_continuous, height=1.5,
plot_kws={"s": 2, "alpha": 0.2});

왼쪽 상단 모서리에 있는 몇 가지 기능 간에 이상한 관계가 있는 것 같습니다.
Location_Easting_OSGR및 Longitude, 뿐만 아니라 Location_Easting_OSGR 및 Latitude는
매우 강한 선형 관계를 갖는 것으로 보입니다.
sns.pairplot(
df_X,
plot_kws={"s": 3, "alpha": 0.2},
hue="Police_Force",
palette="Spectral",
x_vars=["Location_Easting_OSGR", "Location_Northing_OSGR", "Longitude"],
y_vars="Latitude");
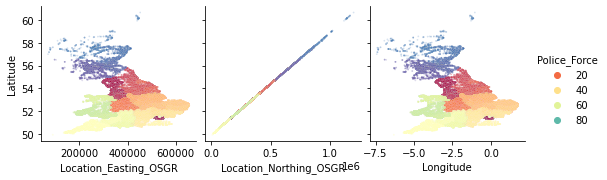
이러한 기능에 지리 정보가 포함되어 있으므로 지리 위치와 관련된 보다 심층적인 EDA가 유용할 수 있습니다.
그러나 지금은 이 쌍 그림에 대한 추가 조사를 호기심 많은 독자에게 맡기고 이산 및 순서 특징에 대한 탐구를 계속할 것입니다.
3.2.2. 이산 및 순서 기능
이산 또는 순서 피쳐에서 패턴을 찾는 것은 조금 더 까다롭습니다.
그러나 여기에서도 몇 가지 빠른 판다와 바다에서 태어난 속임수가
데이터 세트에 대한 일반적인 개요를 얻는 데 도움이 될 수 있습니다. 먼저 조사할 열을 선택하겠습니다.
# Create a new dataframe which doesn't contain continuous features
df_discrete = df_X[cols_continuous[~cols_continuous].index]
df_discrete.shape
>>> (317665, 44)항상 그렇듯이 이러한 모든 기능을 조사하는 방법에는 여러 가지가 있습니다.
seaborn 을 서브플롯에 대한 편리한 for 루프 stripplot()와 함께 사용하여 한 가지 예를 시도해 보겠습니다.zip()
참고 로, y축 방향으로 값을 퍼뜨리려면 하나의 특정(정보를 제공하는) 기능을 선택해야 합니다.
'올바른' 기능이 몇 가지 흥미로운 패턴을 식별하는 데 도움이 될 수 있지만 일반적으로 연속 기능은 트릭을 수행해야 합니다.
이러한 종류의 플롯에서 주요 관심은 각 불연속 값에 포함된 샘플 수를 확인하는 것입니다.
import numpy as np
# Establish number of columns and rows needed to plot all features
n_cols = 5
n_elements = len(df_discrete.columns)
n_rows = np.ceil(n_elements / n_cols).astype("int")
# Specify y_value to spread data (ideally a continuous feature)
y_value = df_X["Age_of_Driver"]
# Create figure object with as many rows and columns as needed
fig, axes = plt.subplots(
ncols=n_cols, nrows=n_rows, figsize=(15, n_rows * 2.5))
# Loop through features and put each subplot on a matplotlib axis object
for col, ax in zip(df_discrete.columns, axes.ravel()):
sns.stripplot(data=df_X, x=col, y=y_value, ax=ax,
palette="tab10", size=1, alpha=0.5)
plt.tight_layout();
여기에 언급할 사항이 너무 많으므로 몇 가지만 중점적으로 살펴보겠습니다.
특히, 값이 특정 패턴으로 나타나거나 일부 범주가 다른 범주보다 훨씬 덜 자주 나타나는 6가지 기능에 초점을 맞추겠습니다.
그리고 상황을 약간 흔들기 위해 이제 이 Longitude기능을 사용하여 y축에 걸쳐 값을 늘리겠습니다.
# Specify features of interest
selected_features = ["Vehicle_Reference_df_res", "Towing_and_Articulation",
"Skidding_and_Overturning", "Bus_or_Coach_Passenger",
"Pedestrian_Road_Maintenance_Worker", "Age_Band_of_Driver"]
# Create a figure with 3 x 2 subplots
fig, axes = plt.subplots(ncols=3, nrows=2, figsize=(16, 8))
# Loop through these features and plot entries from each feature against `Latitude`
for col, ax in zip(selected_features, axes.ravel()):
sns.stripplot(data=df_X, x=col, y=df_X["Latitude"], ax=ax,
palette="tab10", size=2, alpha=0.5)
plt.tight_layout();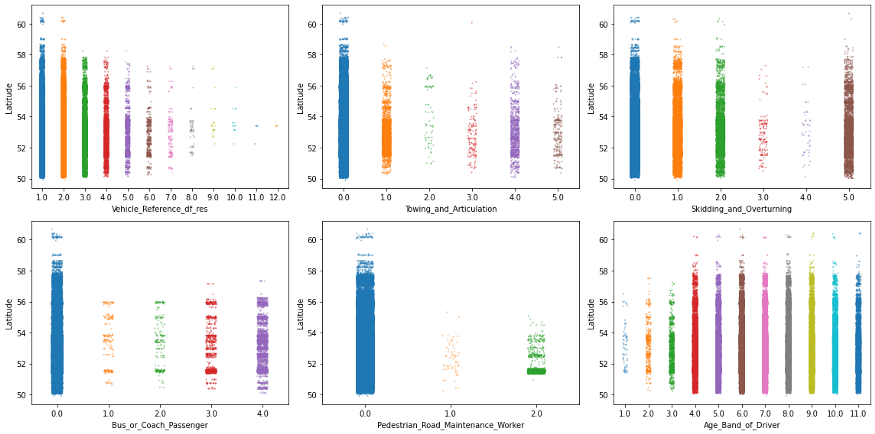
이러한 종류의 플롯은 이미 매우 유익하지만 한 번에 많은 데이터 포인트가 있는 영역을 가립니다.
예를 들어, 위도 52위의 일부 플롯에는 점 밀도가 높은 것으로 보입니다.
violineplot따라서 (또는 boxenplot그 boxplot문제에 대해) 와 같은 적절한 플롯으로 자세히 살펴보겠습니다 .
그리고 한 단계 더 나아가 각 시각화를 로 구분하겠습니다 Urban_or_Rural_Area.
# Create a figure with 3 x 2 subplots
fig, axes = plt.subplots(ncols=3, nrows=2, figsize=(16, 8))
# Loop through these features and plot entries from each feature against `Latitude`
for col, ax in zip(selected_features, axes.ravel()):
sns.violinplot(data=df_X, x=col, y=df_X["Latitude"], palette="Set2",
split=True, hue="Urban_or_Rural_Area", ax=ax)
plt.tight_layout();
흥미로운! 기능에 대한 일부 값은 시골 지역보다 도시 지역에서 더 자주 발생한다는 것을 알 수 있습니다(반대의 경우도 마찬가지).
또한 의심되는 바와 같이 위도 51.5에 고밀도 피크가 있는 것으로 보입니다.
이것은 런던 주변의 인구 밀도가 높은 지역(51.5074°) 때문일 가능성이 매우 높습니다.
3.3. 기능 관계
마지막으로 기능 간의 관계를 살펴보겠습니다. 더 정확하게 상관 관계가 있습니다.
가장 빠른 방법은 팬더의 .corr()기능을 사용하는 것입니다.
이제 모든 수치적 특징에 대한 특징 대 특징 상관 행렬을 계산해 보겠습니다.
참고 : 데이터 세트와 기능의 종류(예: 순서 또는 연속 기능) 에 따라
상관 관계를 계산하는 spearman방법 대신 방법 을 사용하는 것이 좋습니다.
Pearson 상관 관계는 두 개의 연속 변수 간의 선형 관계를 평가하는 pearson
반면 Spearman 상관 관계는 각 기능에 대한 순위 값을 기반으로 단조 관계를 평가합니다.
이 상관 행렬의 해석을 돕기 위해 Seaborn을 사용 하여 시각화해 보겠습니다..heatmap()
# Computes feature correlation
df_corr = df_X.corr(method="pearson")
# Create labels for the correlation matrix
labels = np.where(np.abs(df_corr)>0.75, "S",
np.where(np.abs(df_corr)>0.5, "M",
np.where(np.abs(df_corr)>0.25, "W", "")))
# Plot correlation matrix
plt.figure(figsize=(15, 15))
sns.heatmap(df_corr, mask=np.eye(len(df_corr)), square=True,
center=0, annot=labels, fmt='', linewidths=.5,
cmap="vlag", cbar_kws={"shrink": 0.8});
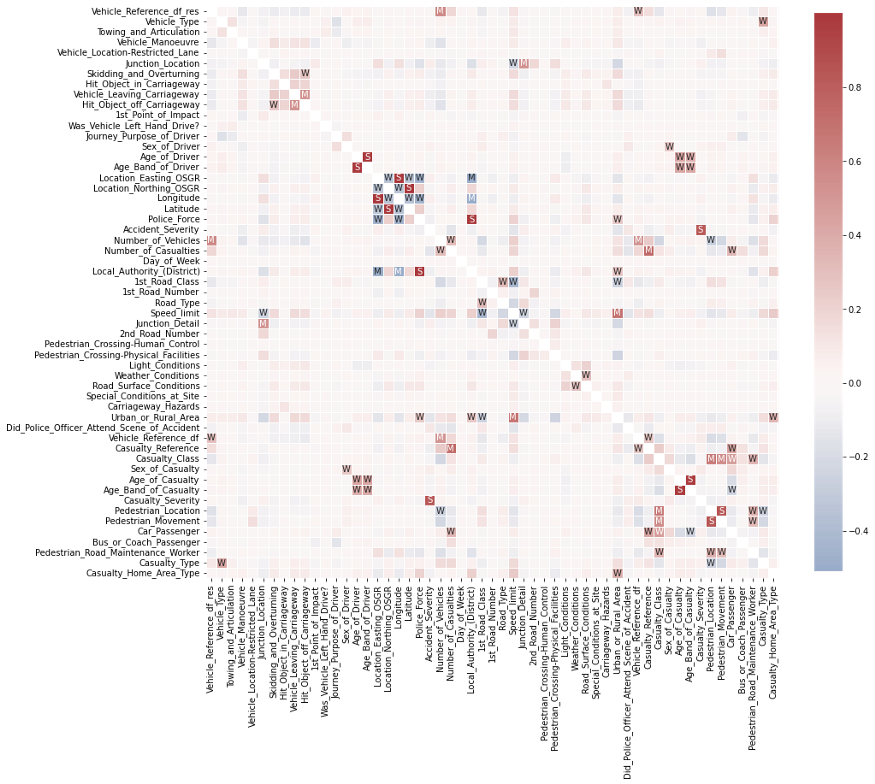
이것은 이미 매우 흥미로워 보입니다.
일부 기능 간에는 몇 가지 매우 강력한 상관 관계가 있습니다.
이제 이러한 서로 다른 상관 관계를 모두 실제로 정렬하는 데 관심이 있다면 다음과 같이 할 수 있습니다.
# Creates a mask to remove the diagonal and the upper triangle.
lower_triangle_mask = np.tril(np.ones(df_corr.shape), k=-1).astype("bool")
# Stack all correlations, after applying the mask
df_corr_stacked = df_corr.where(lower_triangle_mask).stack().sort_values()
# Showing the lowest and highest correlations in the correlation matrix
display(df_corr_stacked)
>>> Local_Authority_(District) Longitude -0.509343
>>> Location_Easting_OSGR -0.502919
>>> ...
>>> Longitude Location_Easting_OSGR 0.999363
>>> Latitude Location_Northing_OSGR 0.999974
>>> Length: 1485, dtype: float64
보시다시피 기능 상관 관계에 대한 조사는 매우 유익할 수 있습니다.
그러나 한 번에 모든 것을 보는 것이 때로는 도움이 되기보다 혼란스러울 수 있습니다.
따라서 다음과 같은 하나의 기능에만 집중 df_X.corrwith(df_X["Speed_limit"])하는 것이 더 나은 접근 방식일 수 있습니다.
또한 기능에 여전히 많은 결측값이나 극단적인 이상값이 포함되어 있으면 상관 관계가 기만적일 수 있습니다.
따라서 이러한 상관 관계를 조사하기 전에 먼저 특성 행렬이 제대로 준비되었는지 확인하는 것이 항상 중요합니다.
3.4. 내용 조사의 결론
이 세 번째 조사가 끝나면 데이터 세트의 콘텐츠를 더 잘 이해해야 합니다.
우리는 가치 분포, 특징 패턴 및 특징 상관 관계를 살펴보았습니다.
그러나 이것이 가능한 모든 콘텐츠 조사 및 데이터 정리 단계는 아닙니다. 추
가 단계는 예를 들어 이상값 감지 및 제거, 기능 엔지니어링 및 변환 등입니다.
적절하고 상세한 EDA는 시간이 걸립니다!
데이터 세트의 또 다른 결함을 해결한 후 처음으로 돌아가게 만드는 매우 반복적인 프로세스입니다.
이것은 정상입니다! 데이터 과학 프로젝트의 80%가 데이터 준비 및 EDA라고 흔히 말하는 이유입니다.
'Daily Review' 카테고리의 다른 글
| 데이터 사이언스 관련 직무 급여 데이터셋을 분석했습니다. (0) | 2022.09.05 |
|---|---|
| 데이터 시각화(Data Visualize) : 알아야 할 가장 중요한 5가지 (0) | 2022.09.04 |
| Python을 사용한 고급 탐색 데이터 분석(EDA) - 2 (0) | 2022.09.04 |
| Python을 사용한 고급 탐색 데이터 분석(EDA) - 1 (0) | 2022.09.03 |
| Python을 사용한 Spotify 데이터 분석 및 시각화 (2) (0) | 2022.09.03 |




댓글