반응형

소개
Spotify에는 귀하를어디에나 있는노래와 그 기능의 데이터베이스. 예를 들어, 좋아하는 노래에서 시각적 통찰력을 얻거나 재생을 웹 응용 프로그램에 통합할 수 있습니다. 또한 강력한 노래 검색 엔진을 사용할 수 있을 뿐만 아니라 좋아하는 노래를 더 많이 들을 수 있도록 도와주는 추천 시스템도 있습니다.
앞선 프로젝트 1에 이어서 진행합니다.
트랙의 기능 시각화
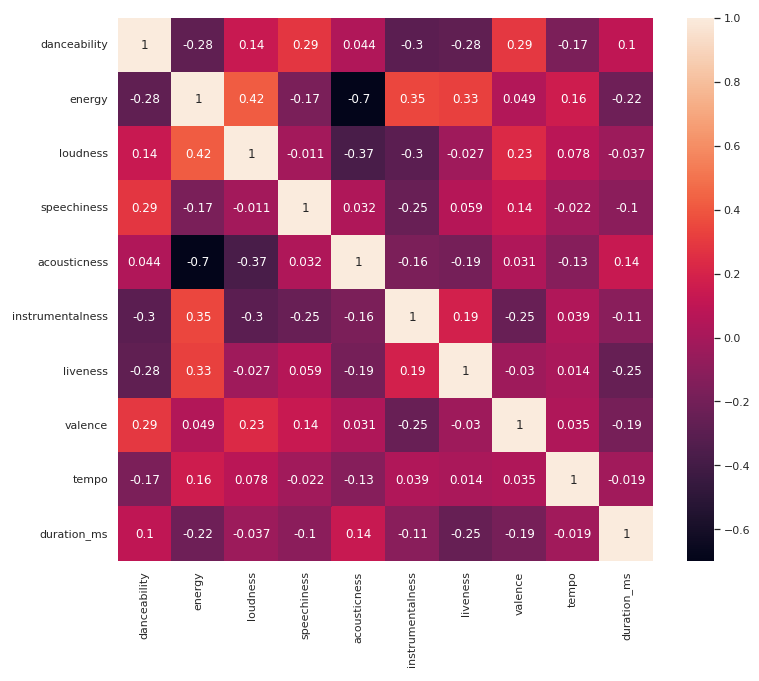
다음은 트랙 기능의 상관 행렬입니다.
import seaborn as sn
sn.set(rc = {'figure.figsize':(12,10)})
sn.heatmap(tf_df.corr(), annot=True)
plt.show()
특정 변수 쌍에 대해 이변량 KDE를 표시할 수도 있습니다.
sn.set(rc = {'figure.figsize':(20,20)})
sn.jointplot(data=tf_df, x="loudness", y="energy", kind="kde")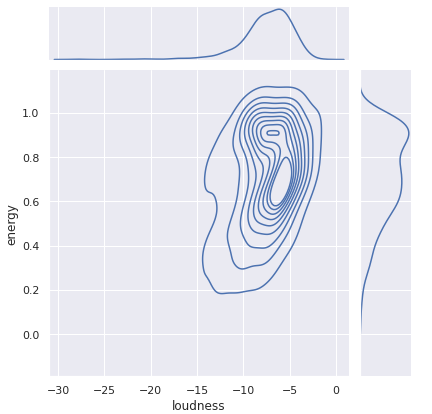
가장 인기 있는 트랙은 데이터세트의 모든 트랙과 어떻게 다릅니까?
선택된 특징의 평균값이 주어졌을 때 해당 세트의 특징 시각화 그래프를 그려서 알아봅시다.
feat_cols = ['danceability', 'energy', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence']
top_100_feat = pd.DataFrame(columns=feat_cols)
for i, track in by_track_pop[:100].iterrows():
features = tf_df[tf_df['id'] == track['track_id']]
top_100_feat = top_100_feat.append(features, ignore_index=True)
top_100_feat = top_100_feat[feat_cols]
from sklearn import preprocessing
mean_vals = pd.DataFrame(columns=feat_cols)
mean_vals = mean_vals.append(top_100_feat.mean(), ignore_index=True)
mean_vals = mean_vals.append(tf_df[feat_cols].mean(), ignore_index=True)
print(mean_vals)
import plotly.graph_objects as go
import plotly.offline as pyo
fig = go.Figure(
data=[
go.Scatterpolar(r=mean_vals.iloc[0], theta=feat_cols, fill='toself', name='Top 100'),
go.Scatterpolar(r=mean_vals.iloc[1], theta=feat_cols, fill='toself', name='All'),
],
layout=go.Layout(
title=go.layout.Title(text='Feature comparison'),
polar={'radialaxis': {'visible': True}},
showlegend=True
)
)
#pyo.plot(fig)
fig.show()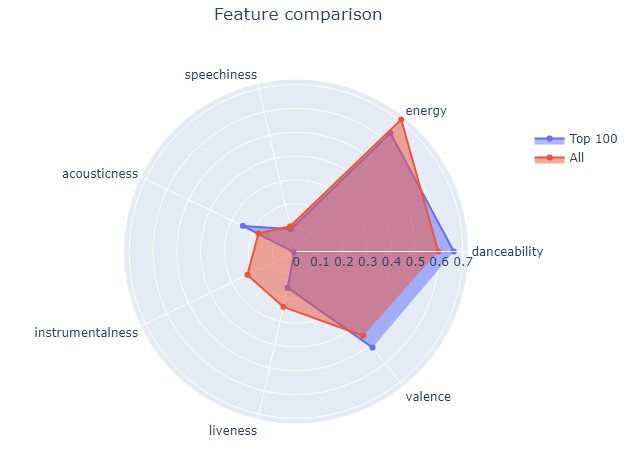
가장 대중적인 곡들이 조금 더 춤을 출 수 있고 더 밸런싱이 있는 것 같다. 그들은 또한 도구성이 없고 활력이 거의 없습니다.
추천 받기
분석의 마지막 단계는 아티스트 ID, 장르 및 트랙 ID를 기준으로 트랙 추천을 받는 것입니다.
출력은 무작위이므로 Spotify는 콘텐츠 제안이 부족하지 않습니다.
rec = sp.recommendations(seed_artists=["3PhoLpVuITZKcymswpck5b"], seed_genres=["pop"], seed_tracks=["1r9xUipOqoNwggBpENDsvJ"], limit=100)
for track in rec['tracks']:
print(track['artists'][0]['name'], track['name'])

반응형
'Daily Review' 카테고리의 다른 글
| Python을 사용한 고급 탐색 데이터 분석(EDA) - 2 (0) | 2022.09.04 |
|---|---|
| Python을 사용한 고급 탐색 데이터 분석(EDA) - 1 (0) | 2022.09.03 |
| Python을 사용한 Spotify 데이터 분석 및 시각화 (1) (0) | 2022.09.03 |
| CRM 분석, RFM 분석 (1) | 2022.09.02 |
| model.fit() 데이터 사이언티스트를 위한 자리는 없습니다. (0) | 2022.09.02 |




댓글