거의 모든 테이블 형식 데이터 세트를 빠르게 처리하는 방법
새 데이터 세트에 대한 좋은 느낌을 얻는 것이 항상 쉬운 일이 아니며 시간이 걸립니다. 그러나 훌륭하고 광범위한 탐색적 데이터 분석(EDA)은 데이터 세트를 이해하고, 데이터가 어떻게 연결되어 있는지, 데이터 세트를 적절하게 처리하기 위해 수행해야 하는 작업에 대한 느낌을 얻는 데 많은 도움이 될 수 있습니다.
이 기사에서는 여러 가지 유용한 EDA 루틴을 다룰 것입니다. 그러나 내용을 짧고 간결하게 유지하기 위해 항상 더 깊이 파고들거나 모든 의미를 설명하지 못할 수도 있습니다. 그러나 실제로 데이터 세트를 완전히 이해하기 위해 적절한 EDA에 충분한 시간을 투자하는 것은 훌륭한 데이터 과학 프로젝트의 핵심 부분입니다. 일반적으로 데이터 준비 및 탐색에 80%의 시간을 할애하고 실제 기계 학습 모델링에 20%만 할애할 것입니다.
구조, 품질 및 내용 조사
전반적으로 EDA 접근 방식은 매우 반복적입니다. 조사가 끝나면 모든 것을 다시 한 번 수행해야 하는 무언가를 발견할 수 있습니다. 정상입니다! 그러나 적어도 약간의 구조를 부과하기 위해 귀하의 조사를 위해 다음 구조를 제안합니다.
- 구조 조사(Structure investigation) : 데이터 세트의 일반적인 모양과 피처의 데이터 유형을 탐색합니다.
- 품질 조사(Quality investigation) : 중복, 누락된 값 및 원치 않는 항목과 관련하여 데이터 세트의 일반적인 품질에 대한 느낌을 얻습니다.
- 콘텐츠 조사(Content investigation) : 데이터 세트의 구조와 품질이 이해되면 기능 값에 대해 더 심층적인 탐색을 수행하고 다양한 기능이 서로 어떻게 관련되어 있는지 확인할 수 있습니다.
하지만 먼저 흥미로운 데이터 세트를 찾아야 합니다. OpenML 에서 도로 안전 데이터 세트 를 로드해 보겠습니다 .
from sklearn.datasets import fetch_openml
# Download the dataset from openml
dataset = fetch_openml(data_id=42803, as_frame=True)
# Extract feature matrix X and show 5 random samples
df_X = dataset["frame"]1. Structure investigation
특성 행렬 X 의 내용을 보기 전에 먼저 데이터 세트의 일반적인 구조를 살펴보겠습니다.
예를 들어, 데이터 세트에는 몇 개의 열과 행이 있습니까?
그리고 이러한 기능에는 얼마나 많은 다른 데이터 유형이 포함되어 있습니까?
# Show size of the dataset
df_X.shape
>>> (363243, 67)
import pandas as pd
# Count how many times each data type is present in the dataset
pd.value_counts(df_X.dtypes)
>>> float64 61
>>> object 6
>>> dtype: int64
1.1. 숫자가 아닌 기능의 구조
데이터 유형은 숫자 및 비숫자일 수 있습니다. 먼저 숫자가 아닌 항목 에 대해 자세히 살펴보겠습니다 .
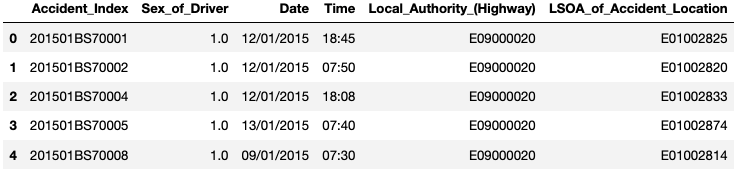
수치적 특징 이지만 Sex_of_Driver어쩐지 수치적이지 않은 것으로 저장되어 있었습니다.
이것은 때때로 데이터 기록의 일부 오타로 인해 발생합니다. 이러한 종류의 것들은 데이터 준비 중에 처리해야 합니다.
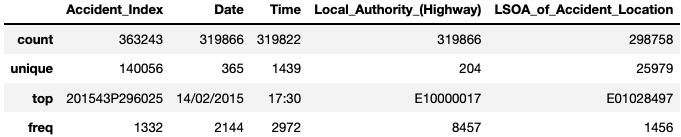
이것이 처리되면 .describe()함수를 사용하여 각 비숫자 기능이 갖는 고유한 값의 수와 가장 두드러진 값이 나타나는 빈도를 조사 할 수 있습니다 df_X.describe(exclude="number").
1.2. 수치적 특징의 구조
다음으로 수치적 특징에 대해 자세히 살펴보겠습니다. 보다 정확하게는 이러한 각 기능에 고유한 값이 몇 개인지 조사해 보겠습니다.
# For each numerical feature compute number of unique entries
unique_values = df_X.select_dtypes(
include="number").nunique().sort_values()
# Plot information with y-axis in log-scale
unique_values.plot.bar(logy=True, figsize=(15, 4),
title="Unique values per feature");

1.3. 구조 조사의 결론
이 첫 번째 조사가 끝나면 데이터 세트의 일반적인 구조를 더 잘 이해해야 합니다.
샘플 및 기능의 수, 각 기능의 데이터 유형 유형, 이진, 순서, 범주형 또는 연속형의 수.
그러한 종류의 정보를 얻는 다른 방법으로 df_X.info()또는 df_X.describe()를 사용할 수도 있습니다.
2. Quality Investigation
이러한 기능에 저장된 실제 콘텐츠에 초점을 맞추기 전에 먼저 데이터 세트의 일반적인 품질을 살펴보겠습니다.
목표는 중복 , 누락된 값 및 원치 않는 항목 또는 기록 오류 와 관련하여 데이터 세트에 대한 전체 보기를 갖는 것 입니다.
2.1. 중복
중복은 동일한 샘플 포인트를 여러 번 나타내는 항목입니다.
예를 들어 두 명의 다른 사람이 측정값을 두 번 등록한 경우입니다.
각 데이터 세트에 고유한 식별자 기능(예: 각 새 샘플에 고유한 색인 번호 또는 기록 시간)이 있을 수 있으므로
이러한 중복을 감지하는 것이 항상 쉬운 것은 아닙니다. 따라서 먼저 무시할 수 있습니다.
그리고 데이터 세트의 중복 수를 알게 되면 간단히 .drop_duplicates().
# Check number of duplicates while ignoring the index feature
n_duplicates = df_X.drop(labels=["Accident_Index"], axis=1).duplicated().sum()
print(f"You seem to have {n_duplicates} duplicates in your database.")
>>> You seem to have 22 duplicates in your database.
# Extract column names of all features, except 'Accident_Index'
columns_to_consider = df_X.drop(labels=["Accident_Index"], axis=1).columns
# Drop duplicates based on 'columns_to_consider'
df_X = df_X.drop_duplicates(subset=columns_to_consider)
df_X.shape
>>> (363221, 67)2.2. 누락된 값
조사할 가치가 있는 또 다른 품질 문제는 결측값 입니다.
일부 누락된 값이 있는 것은 정상입니다.
이 단계에서 식별하고자 하는 것은 데이터 세트의 큰 구멍, 즉 많은 결측값이 있는 샘플 또는 기능입니다.
2.2.1. 샘플당
표본당 결측값의 수를 보기 위해 여러 옵션이 있습니다.
가장 간단한 방법은 의 출력을 df_X.isna()다음과 같이 시각화하는 것입니다.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 8))
plt.imshow(df_X.isna(), aspect="auto", interpolation="nearest", cmap="gray")
plt.xlabel("Column Number")
plt.ylabel("Sample Number");

이 그림은 360,000개의 개별 샘플 각각을 y축에 표시하고 67개 기능 중 하나라도 결측값을 포함하는 경우 x축에 표시합니다. 이것은 이미 유용한 플롯이지만 더 나은 접근 방식은 missingno 라이브러리를 사용하여 다음과 같은 플롯을 얻는 것입니다.
import missingno as msno
msno.matrix(df_X, labels=True, sort="descending");

이 두 플롯에서 데이터 세트에 큰 구멍이 있음을 알 수 있습니다. 일부 샘플에서 특성 값의 50% 이상이 누락되어 있기 때문입니다. 이러한 샘플의 경우 누락된 값을 일부 대체 값으로 채우는 것은 좋은 생각이 아닐 수 있습니다.
따라서 결측값이 20% 이상인 샘플을 삭제해 보겠습니다. 임계값은 이 그림의 오른쪽에 있는 '데이터 완전성' 열의 정보에서 영감을 받았습니다.
df_X = df_X.dropna(thresh=df_X.shape[1] * 0.80, axis=0).reset_index(drop=True)
df_X.shape
>>> (319790, 67)2.2.2. 기능별
다음 단계로 이제 특성당 누락된 값의 수를 살펴보겠습니다.
이를 위해 몇 가지 속임수를 사용 하여 pandas 누락된 값의 비율을 빠르게 식별할 수 있습니다 .
df_X.isna().mean().sort_values().plot(
kind="bar", figsize=(15, 4),
title="Percentage of missing values per feature",
ylabel="Ratio of missing values per feature");

이 그림에서 대부분의 기능에 결측값이 포함되어 있지 않음을 알 수 있습니다.
그럼에도 불구하고, 2nd_Road_Class에는 여전히 많은 결측값이 포함되어 있습니다.
이제 결측값이 15% 이상인 기능을 제거해 보겠습니다.
df_X = df_X.dropna(thresh=df_X.shape[0] * 0.85, axis=1)
df_X.shape
>>> (319790, 60)2.2.3. 작은 쪽지
결측값 : 결측값을 제거하는 엄격한 순서는 없습니다. 일부 데이터 세트의 경우 샘플보다 기능을 먼저 처리하는 것이 더 나을 수 있습니다. 또한 기능당 누락된 값을 삭제하기로 결정한 임계값 또는 데이터 세트에서 데이터 세트로의 샘플 변경 사항은 나중에 데이터 세트로 수행하려는 작업에 따라 다릅니다.
또한 , 지금까지는 데이터 세트의 큰 구멍만 해결했으며 작은 간격을 채우는 방법은 아직 다루지 않았습니다. 이것은 다른 게시물에 대한 내용입니다.
'Daily Review' 카테고리의 다른 글
| Python을 사용한 고급 탐색 데이터 분석(EDA) - 3 (0) | 2022.09.04 |
|---|---|
| Python을 사용한 고급 탐색 데이터 분석(EDA) - 2 (0) | 2022.09.04 |
| Python을 사용한 Spotify 데이터 분석 및 시각화 (2) (0) | 2022.09.03 |
| Python을 사용한 Spotify 데이터 분석 및 시각화 (1) (0) | 2022.09.03 |
| CRM 분석, RFM 분석 (1) | 2022.09.02 |




댓글