거의 모든 테이블 형식 데이터 세트를 빠르게 처리하는 방법
새 데이터 세트에 대한 좋은 느낌을 얻는 것이 항상 쉬운 일이 아니며 시간이 걸립니다. 그러나 훌륭하고 광범위한 탐색적 데이터 분석(EDA)은 데이터 세트를 이해하고, 데이터가 어떻게 연결되어 있는지, 데이터 세트를 적절하게 처리하기 위해 수행해야 하는 작업에 대한 느낌을 얻는 데 많은 도움이 될 수 있습니다.
이 기사에서는 여러 가지 유용한 EDA 루틴을 다룰 것입니다. 그러나 내용을 짧고 간결하게 유지하기 위해 항상 더 깊이 파고들거나 모든 의미를 설명하지 못할 수도 있습니다. 그러나 실제로 데이터 세트를 완전히 이해하기 위해 적절한 EDA에 충분한 시간을 투자하는 것은 훌륭한 데이터 과학 프로젝트의 핵심 부분입니다. 일반적으로 데이터 준비 및 탐색에 80%의 시간을 할애하고 실제 기계 학습 모델링에 20%만 할애할 것입니다.
구조, 품질 및 내용 조사
전반적으로 EDA 접근 방식은 매우 반복적입니다. 조사가 끝나면 모든 것을 다시 한 번 수행해야 하는 무언가를 발견할 수 있습니다. 정상입니다! 그러나 적어도 약간의 구조를 부과하기 위해 귀하의 조사를 위해 다음 구조를 제안합니다.
- 구조 조사(Structure investigation) : 데이터 세트의 일반적인 모양과 피처의 데이터 유형을 탐색합니다.
- 품질 조사(Quality investigation) : 중복, 누락된 값 및 원치 않는 항목과 관련하여 데이터 세트의 일반적인 품질에 대한 느낌을 얻습니다.
- 콘텐츠 조사(Content investigation) : 데이터 세트의 구조와 품질이 이해되면 기능 값에 대해 더 심층적인 탐색을 수행하고 다양한 기능이 서로 어떻게 관련되어 있는지 확인할 수 있습니다.
이번 내용은 1에 이어서 진행됩니다.
2.3. 원치 않는 항목 및 녹음 오류
데이터세트에서 품질 문제의 또 다른 원인은 원치 않는 항목이나 기록 오류로 인한 것일 수 있습니다. 이러한 샘플을 단순 이상값과 구별하는 것이 중요합니다. 이상치는 지정된 기능 분포에 대해 비정상적인 데이터 포인트인 반면 원치 않는 항목이나 기록 오류는 애초에 존재해서는 안 되는 샘플입니다 .
예를 들어, 스위스에서 45°C의 온도 기록은 이상값('매우 이례적인')일 수 있지만 90°C에서의 기록은 오류가 될 수 있습니다. 유사하게, 몽블랑 정상에서의 온도 기록은 물리적으로 가능할 수 있지만 대부분 스위스 도시에 대한 데이터 세트에 포함되어서는 안 됩니다.
물론 이러한 오류 및 원치 않는 항목을 감지하고 이상값과 구별하는 것이 항상 간단한 것은 아니며 데이터 세트에 크게 의존합니다. 이에 대한 한 가지 접근 방식은 데이터 세트를 전체적으로 보고 매우 특이한 패턴을 식별할 수 있는지 확인하는 것입니다.
2.3.1. 수치적 특징
데이터 세트의 이 전역 보기를 플롯하려면 최소한 수치 기능에 대해 pandas' .plot()함수를 사용하고 다음 매개변수와 결합할 수 있습니다.
- lw=0: lw선 너비를 나타냅니다. 0어떤 라인도 표시하고 싶지 않음을 의미합니다.
- marker=".": 선 대신 플롯 .에 각 데이터 포인트의 마커 로 사용하도록 지시합니다.
- subplots=True: 별도의 서브플롯에 각 기능을 플롯하도록 subplots지시 합니다.pandas
- layout=(-1, 4): 이 매개변수는 pandas서브플롯에 사용할 행과 열 수를 알려줍니다. " -1필요한 만큼"을 2의미하고 행당 2개의 열을 사용하는 것을 의미합니다.
- figsize=(15, 30), markersize=1: 피규어가 충분히 큰지 확인하기 위해서는 대략적인 피처 개수만큼의 피규어 높이를 가지고 markersize그에 따라 조정하는 것을 권장합니다.
이 플롯은 어떻게 생겼습니까?
df_X.plot(lw=0,
marker=".",
subplots=True,
layout=(-1, 4),
figsize=(15, 30),
markersize=1);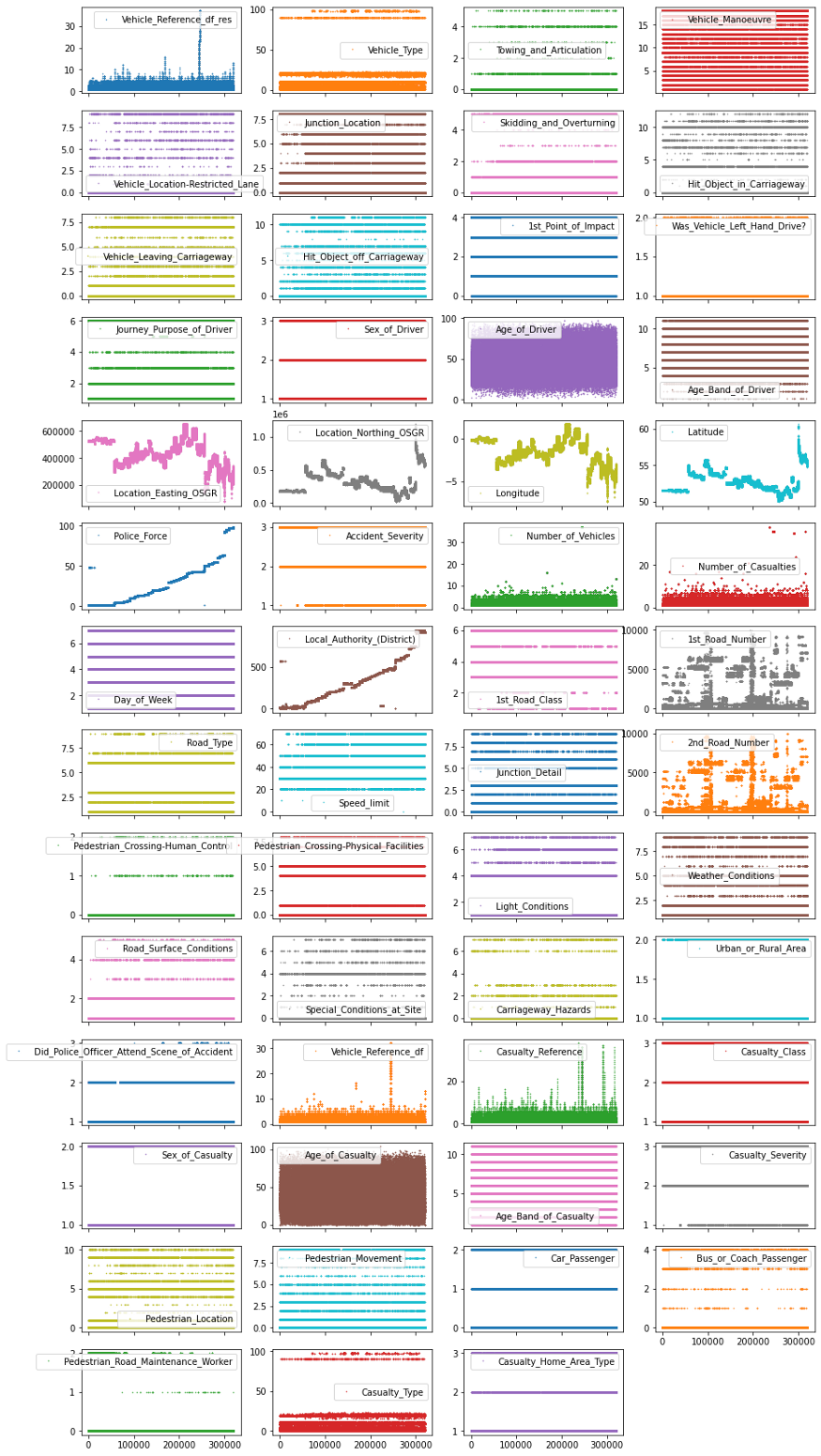
이 그림의 각 점은 데이터 세트의 샘플(즉, 행)이며 각 서브플롯은 다른 기능을 나타냅니다.
y축은 특성 값을 나타내고 x축은 샘플 인덱스를 나타냅니다.
이러한 종류의 플롯은 데이터 정리 및 EDA에 대한 많은 아이디어를 제공할 수 있습니다.
일반적으로 이 시각화 결과에 만족할 때까지 필요한 만큼 많은 시간을 투자하는 것이 좋습니다.
2.3.2. 숫자가 아닌 기능
숫자가 아닌 기능에서 원치 않는 항목 을 식별 하거나 오류 를 기록하는 것은 조금 더 까다롭습니다.
이 시점에서 우리는 데이터 세트의 일반적인 품질만 조사하기를 원합니다.
따라서 우리가 할 수 있는 것은 이러한 비숫자 기능 각각에 포함된 고유 값의 수와 가장 빈번한 범주가 표시되는 빈도를
일반적으로 살펴보는 것입니다.
이렇게 하려면 다음을 사용할 수 있습니다.
df_X.describe(exclude=["number", "datetime])
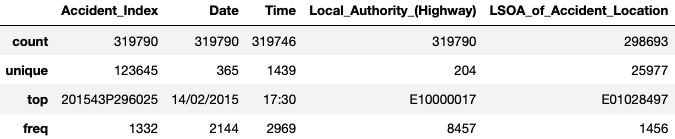
숫자가 아닌 개별 기능에 대한 품질 조사를 잠재적으로 간소화할 수 있는 방법에는 여러 가지가 있습니다.
그들 중 어느 것도 완벽하지 않으며, 그들 모두는 약간의 후속 조사가 필요할 것입니다.
그러나 그러한 솔루션 중 하나를 보여주기 위해 우리가 할 수 있는 일은
모든 비숫자 기능을 반복하고 각각에 대해 고유한 값당 발생 횟수를 그리는 것입니다.
# Create figure object with 3 subplots
fig, axes = plt.subplots(ncols=1, nrows=3, figsize=(12, 8))
# Identify non-numerical features
df_non_numerical = df_X.select_dtypes(exclude=["number", "datetime"])
# Loop through features and put each subplot on a matplotlib axis object
for col, ax in zip(df_non_numerical.columns, axes.ravel()):
# Selects one single feature and counts number of unique value
df_non_numerical[col].value_counts().plot(
# Plots this information in a figure with log-scaled y-axis
logy=True, title=col, lw=0, marker=".", ax=ax)
plt.tight_layout();
우리는 가장 빈번한 사고(즉 Accident_Index, )가 100명 이상이 관련되었음을 알 수 있습니다.
조금 더 깊이 파고들면(즉, 이 사고의 개별적인 특징을 살펴보면)
이 사고가 2015년 2월 24일 11시 55분에 영국 카디프에서 발생했음을 확인할 수 있습니다.
빠른 인터넷 검색은 이 항목이 연금 수급자로 가득 찬 미니버스를 포함하여
운 좋게도 치명적이지 않은 사고에 해당한다는 것을 보여줍니다.
이러한 다소 독특한 항목으로 무엇을 해야 하는지에 대한 결정은
데이터 세트를 분석하는 사람의 주관적인 손에 다시 한 번 남겨집니다.
WHY에 대한 정당한 이유 없이, 그리고 HOW를 보여주기 위한 의도로만 - 이 데이터 세트에서 가장 자주 발생하는 10가지 사고를 제거해 보겠습니다.
# Collect entry values of the 10 most frequent accidents
accident_ids = df_non_numerical["Accident_Index"].value_counts().head(10).index
# Removes accidents from the 'accident_ids' list
df_X = df_X[~df_X["Accident_Index"].isin(accident_ids)]
df_X.shape
>>> (317665, 60)2.4. 품질 조사의 결론
이 두 번째 조사가 끝나면 데이터 세트의 일반적인 품질을 더 잘 이해할 수 있습니다. 중복, 누락된 값, 원치 않는 항목 또는 기록 오류를 살펴보았습니다. 데이터 세트의 나머지 누락된 값이나 이상값을 해결하는 방법에 대해 아직 논의하지 않았다는 점을 지적하는 것이 중요합니다. 이것은 다음 조사를 위한 작업이지만 이 문서에서는 다루지 않습니다.
3. Content investigation
지금까지 우리는 데이터셋의 일반적인 구조와 품질만을 살펴보았습니다. 이제 한 단계 더 나아가 실제 내용을 살펴보겠습니다. 이상적인 환경에서 이러한 조사는 기능별로 수행됩니다. 그러나 기능이 20~30개 이상 있으면 매우 번거로워집니다.
이러한 이유로(그리고 이 기사를 필요한 만큼 짧게 유지하기 위해) 각 기능에 저장된 콘텐츠와 이들 간의 관계에 대한 매우 빠른 개요를 제공할 수 있는 세 가지 접근 방식을 살펴보겠습니다.
3.1. 기능 분포
각 기능의 가치 분포를 살펴보는 것은 데이터의 내용을 더 잘 이해할 수 있는 좋은 방법입니다.
또한 EDA를 안내하는 데 도움이 될 수 있으며 데이터 정리 및 기능 변환과 관련하여 유용한 정보를 많이 제공합니다.
수치적 특징에 대해 이를 수행하는 가장 빠른 방법은 히스토그램 플롯을 사용하는 것입니다.
운 좋게도 pandas한 번에 여러 기능을 그릴 수 있는 히스토그램 기능이 내장되어 있습니다.
# Plots the histogram for each numerical feature in a separate subplot
df_X.hist(bins=25, figsize=(15, 25), layout=(-1, 5), edgecolor="black")
plt.tight_layout();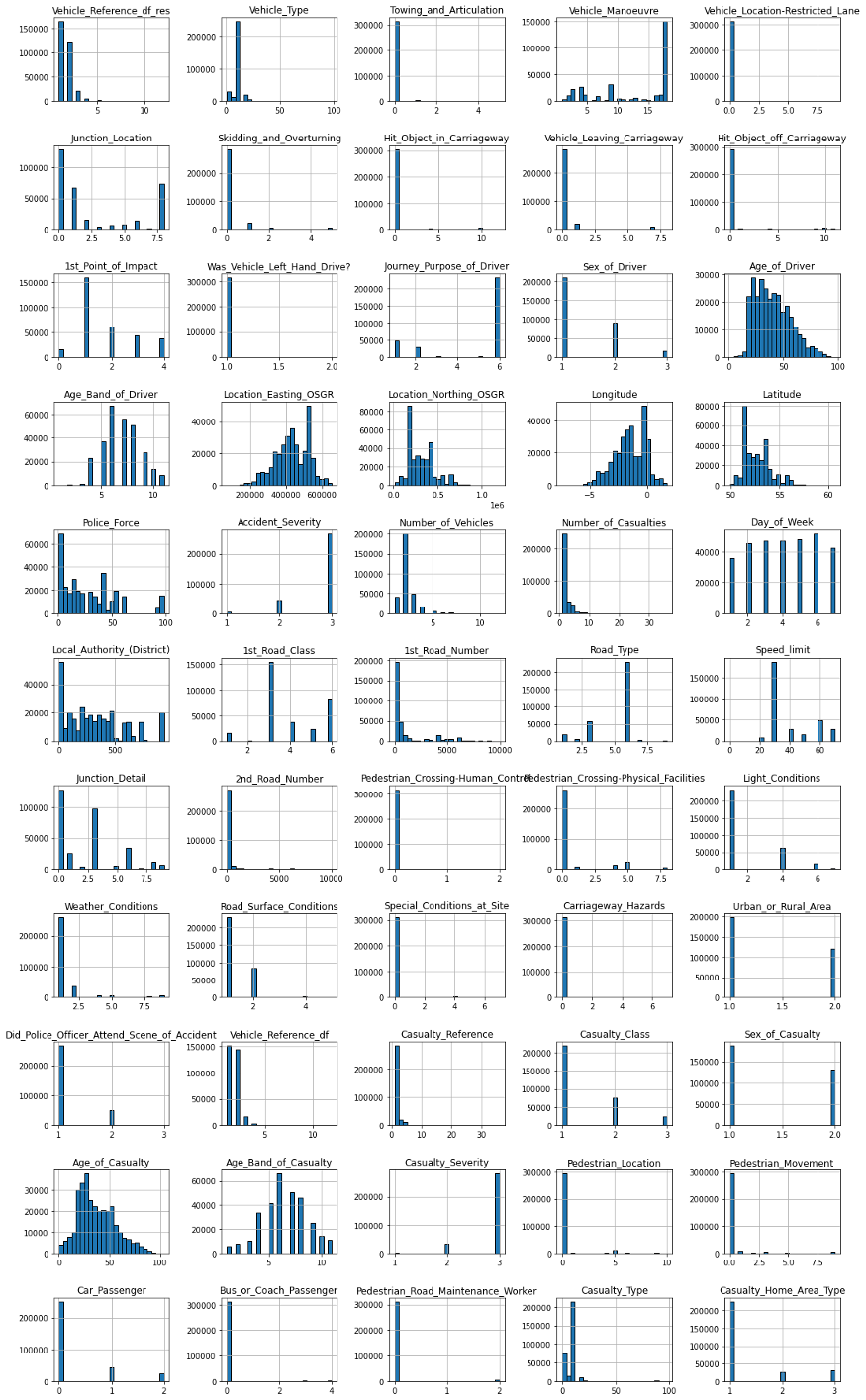
이 플롯에서 볼 수 있는 매우 흥미로운 것들이 많이 있습니다.
예를 들어 각 기능에 대한 가장 빈번한 항목의 비율을 추출하고 해당 정보를 시각화할 수 있습니다.
# Collects for each feature the most frequent entry
most_frequent_entry = df_X.mode()
# Checks for each entry if it contains the most frequent entry
df_freq = df_X.eq(most_frequent_entry.values, axis=1)
# Computes the mean of the 'is_most_frequent' occurrence
df_freq = df_freq.mean().sort_values(ascending=False)
# Show the 5 top features with the highest ratio of singular value content
display(df_freq.head())
# Visualize the 'df_freq' table
df_freq.plot.bar(figsize=(15, 4));
>>> Pedestrian_Crossing-Human_Control 0.995259
>>> Was_Vehicle_Left_Hand_Drive 0.990137
>>> Carriageway_Hazards 0.983646
>>> Towing_and_Articulation 0.983221
>>> Vehicle_Location-Restricted_Lane 0.982088
>>> dtype: float64
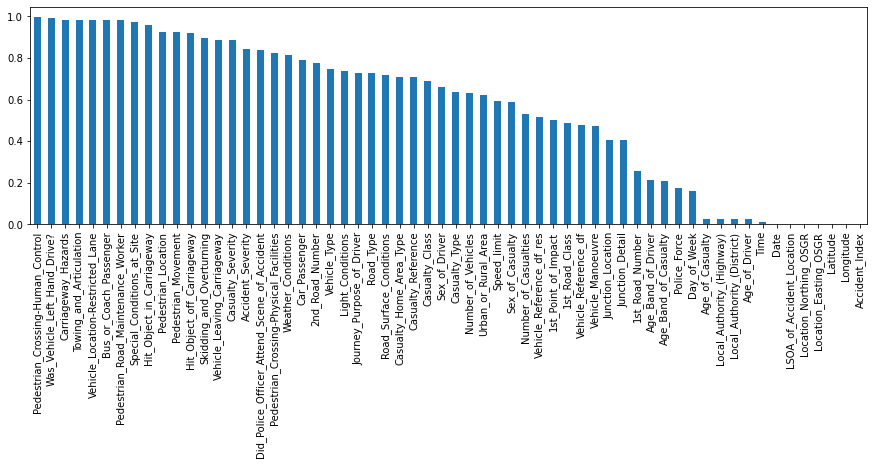
편향된 값 분포 :
특정 종류의 수치적 특징은 비정규 분포를 강하게 나타낼 수도 있습니다.
이 경우 이러한 값을 보다 정규 분포로 만들기 위해 변환하는 방법에 대해 생각할 수 있습니다.
예를 들어 오른쪽으로 치우친 데이터의 경우 로그 변환을 사용할 수 있습니다.
'Daily Review' 카테고리의 다른 글
| 데이터 시각화(Data Visualize) : 알아야 할 가장 중요한 5가지 (0) | 2022.09.04 |
|---|---|
| Python을 사용한 고급 탐색 데이터 분석(EDA) - 3 (0) | 2022.09.04 |
| Python을 사용한 고급 탐색 데이터 분석(EDA) - 1 (0) | 2022.09.03 |
| Python을 사용한 Spotify 데이터 분석 및 시각화 (2) (0) | 2022.09.03 |
| Python을 사용한 Spotify 데이터 분석 및 시각화 (1) (0) | 2022.09.03 |




댓글