
소개
Spotify에는 귀하를어디에나 있는노래와 그 기능의 데이터베이스. 예를 들어, 좋아하는 노래에서 시각적 통찰력을 얻거나 재생을 웹 응용 프로그램에 통합할 수 있습니다. 또한 강력한 노래 검색 엔진을 사용할 수 있을 뿐만 아니라 좋아하는 노래를 더 많이 들을 수 있도록 도와주는 추천 시스템도 있습니다.
전제 조건
Spotify 공식 웹사이트 에서 비용과 노력 없이 가입하는 것부터 시작해 보겠습니다 .
그런 다음 애플리케이션 대시보드 를 열고 "앱 만들기" 버튼을 누르십시오. 필요한 세부 정보를 입력하고 탐색을 준비합니다.
ClientID와 Client Secret을 확보하고 좋아하는 Python IDE를 시작하십시오. 코딩할 시간입니다.
우리는 SpotiPy라는 Spotify API 주변의 래퍼 유틸리티를 사용하여 엔드포인트에 명시적으로 도달하는 대신 멋진 한 줄 길이의 요청을 만들 것입니다. 설치합시다.
!pip install spotipy
그런 다음 CLIENT_ID 및 CLIENT_SECRET 변수에 저장된 Spotify 개발자 자격 증명으로 spotipy.Spotify 개체를 초기화합니다.
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
client_credentials_manager = SpotifyClientCredentials(client_id=CLIENT_ID, client_secret=CLIENT_SECRET)
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager)트랙 및 아티스트 가져오기
다음 단계는 데이터 쿼리입니다. 한 번에 50개 이하의 트랙에 대한 정보만 가져올 수 있습니다. sp.search() 메서드 의 q 매개 변수는 특정 항목을 검색할 수 있는 곳입니다. 참조는 여기 에 있습니다 .
artist_name = []
track_name = []
track_popularity = []
artist_id = []
track_id = []
for i in range(0,1000,50):
track_results = sp.search(q='year:2021', type='track', limit=50,offset=i)
for i, t in enumerate(track_results['tracks']['items']):
artist_name.append(t['artists'][0]['name'])
artist_id.append(t['artists'][0]['id'])
track_name.append(t['name'])
track_id.append(t['id'])
track_popularity.append(t['popularity'])쿼리된 데이터를 Pandas Dataframe에 넣습니다.
import pandas as pd
track_df = pd.DataFrame({'artist_name' : artist_name, 'track_name' : track_name, 'track_id' : track_id, 'track_popularity' : track_popularity, 'artist_id' : artist_id})
print(track_df.shape)
track_df.head()
1000개의 트랙을 각각 수행하는 아티스트에 대한 정보를 추가해 보겠습니다.
artist_popularity = []
artist_genres = []
artist_followers = []
for a_id in track_df.artist_id:
artist = sp.artist(a_id)
artist_popularity.append(artist['popularity'])
artist_genres.append(artist['genres'])
artist_followers.append(artist['followers']['total'])이제 track_df 데이터 프레임에 추가합니다.
track_df = track_df.assign(artist_popularity=artist_popularity, artist_genres=artist_genres, artist_followers=artist_followers)
track_df.head()
Fetch Tracks의 수치적 특징
이제 노래의 수치적 연구에 뛰어들 것입니다. 하지만 먼저 데이터를 가져와야 합니다. 운 좋게도 Spotify는 우리의 목적에 딱 맞는 8,200만 곡에 대한 철저한 통찰력을 제공합니다.
먼저 Spotify API 참조 페이지 에서 트랙 프로필에 기여하는 기능을 알아 보세요.
둘째, 트랙의 기능을 가져와 데이터 프레임에 추가합니다.
track_features = []
for t_id in track_df['track_id']:
af = sp.audio_features(t_id)
track_features.append(af)
tf_df = pd.DataFrame(columns = ['danceability', 'energy', 'key', 'loudness', 'mode', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence', 'tempo', 'type', 'id', 'uri', 'track_href', 'analysis_url', 'duration_ms', 'time_signature'])
for item in track_features:
for feat in item:
tf_df = tf_df.append(feat, ignore_index=True)
tf_df.head()트랙의 기능 데이터 프레임은 다음과 같습니다.

다음 셀에 놓을 중복 열이 몇 개 있습니다.
쓸모없는 열을 몇 개 삭제하고 데이터 프레임의 구조를 확인합시다.
cols_to_drop2 = ['key','mode','type', 'uri','track_href','analysis_url']
tf_df = tf_df.drop(columns=cols_to_drop2)
print(track_df.info())
print(tf_df.info())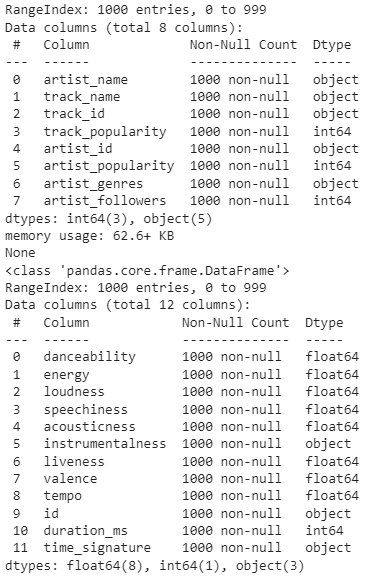
데이터 탐색 및 시각화의 마지막 단계는 열 유형의 추론입니다. 이것은 수동으로 수행됩니다.
track_df['artist_name'] = track_df['artist_name'].astype("string")
track_df['track_name'] = track_df['track_name'].astype("string")
track_df['track_id'] = track_df['track_id'].astype("string")
track_df['artist_id'] = track_df['artist_id'].astype("string")
tf_df['duration_ms'] = pd.to_numeric(tf_df['duration_ms'])
tf_df['instrumentalness'] = pd.to_numeric(tf_df['instrumentalness'])
tf_df['time_signature'] = tf_df['time_signature'].astype("category")
print(track_df.info())
print(tf_df.info())결과 데이터 프레임의 구조는 다음과 같습니다.

지루한 물건 뒤에. 데이터를 더 잘 알아봅시다.
2021년 트렌드 살펴보기
2021년 가장 인기 있는 트랙을 찾고 계신가요?
track_df.sort_values(by=['track_popularity'], ascending=False)[['track_name', 'artist_name']].head(20)
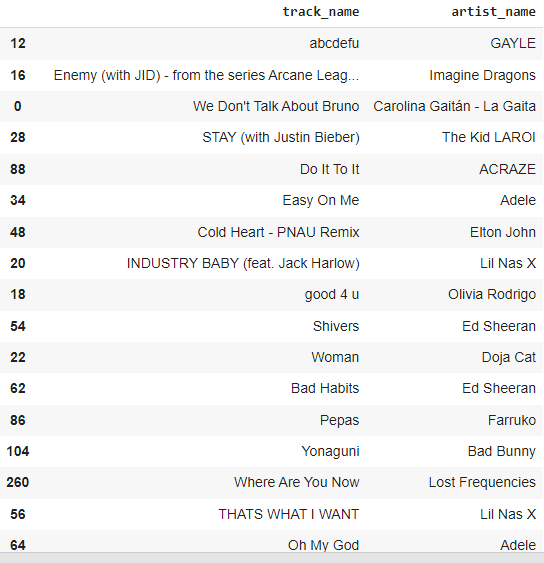
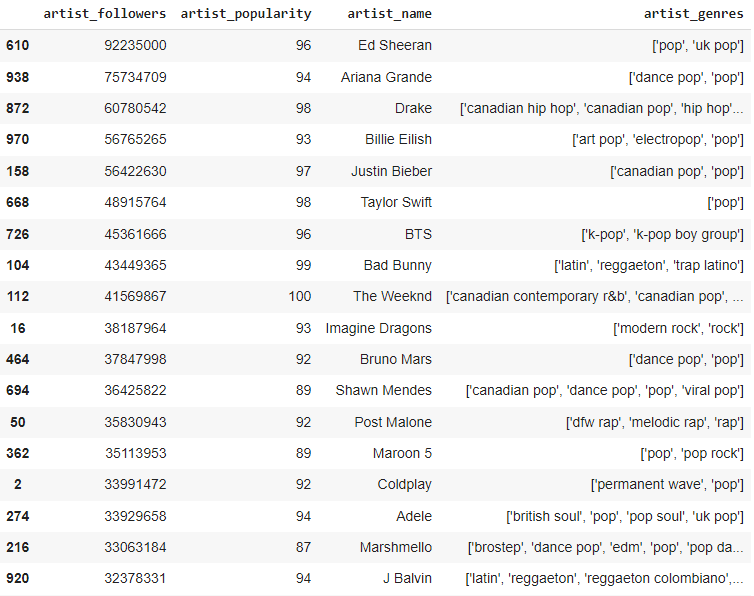
가장 많이 팔로우한 사람은?
by_art_fol = pd.DataFrame(track_df.sort_values(by=['artist_followers'], ascending=False)[['artist_followers','artist_popularity', 'artist_name','artist_genres']])
by_art_fol.astype(str).drop_duplicates().head(20)
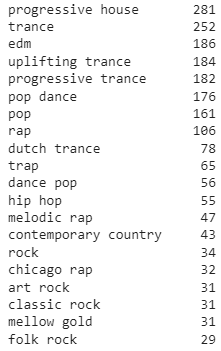
track_df 데이터 프레임에 몇 개의 장르가 있는지 봅시다.
def to_1D(series):
return pd.Series([x for _list in series for x in _list])
to_1D(track_df['artist_genres']).value_counts().head(20)
위의 결과를 시각화하십시오.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize = (14,4))
ax.bar(to_1D(track_df['artist_genres']).value_counts().index[:10],
to_1D(track_df['artist_genres']).value_counts().values[:10])
ax.set_ylabel("Frequency", size = 12)
ax.set_title("Top genres", size = 14)
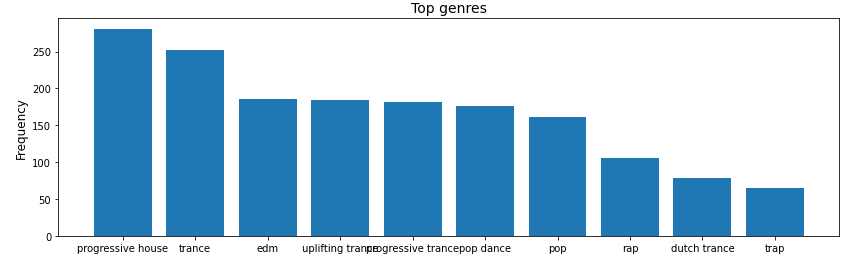
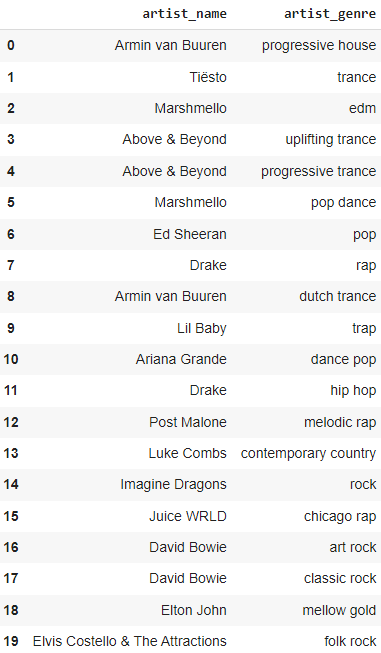
상위 10개 장르의 팔로워 수를 기준으로 정렬된 상위 20명의 아티스트를 찾습니다.
top_10_genres = list(to_1D(track_df['artist_genres']).value_counts().index[:20])
top_artists_by_genre = []
for genre in top_10_genres:
for index, row in by_art_fol.iterrows():
if genre in row['artist_genres']:
top_artists_by_genre.append({'artist_name':row['artist_name'], 'artist_genre':genre})
break
pd.json_normalize(top_artists_by_genre)
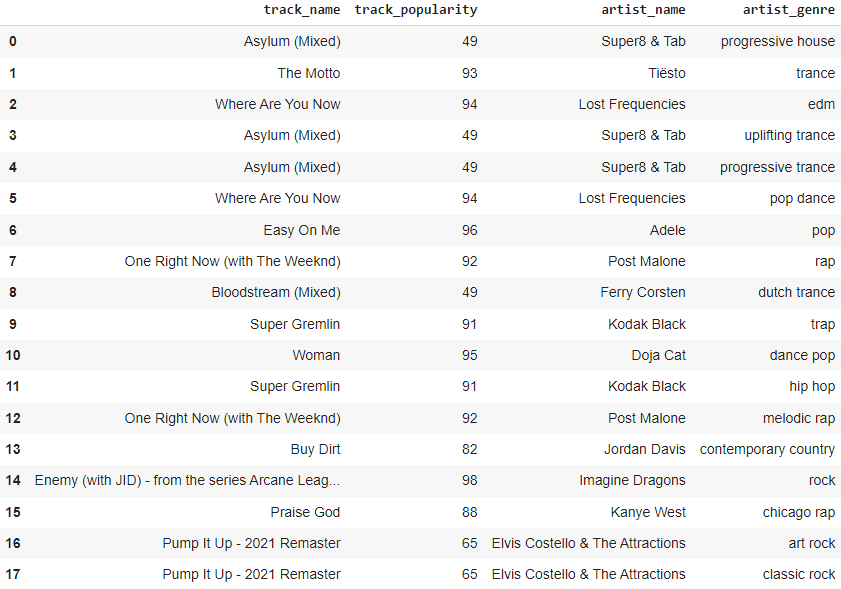
상위 10개 장르별로 인기순으로 정렬된 상위 20개 트랙 찾기:
by_track_pop = pd.DataFrame(track_df.sort_values(by=['track_popularity'], ascending=False)[['track_popularity','track_name', 'artist_name','artist_genres', 'track_id']])
by_track_pop.astype(str).drop_duplicates().head(20)
top_songs_by_genre = []
for genre in top_10_genres:
for index, row in by_track_pop.iterrows():
if genre in row['artist_genres']:
top_songs_by_genre.append({'track_name':row['track_name'], 'track_popularity':row['track_popularity'],'artist_name':row['artist_name'], 'artist_genre':genre})
break
pd.json_normalize(top_songs_by_genre)
'Daily Review' 카테고리의 다른 글
| Python을 사용한 고급 탐색 데이터 분석(EDA) - 1 (0) | 2022.09.03 |
|---|---|
| Python을 사용한 Spotify 데이터 분석 및 시각화 (2) (0) | 2022.09.03 |
| CRM 분석, RFM 분석 (1) | 2022.09.02 |
| model.fit() 데이터 사이언티스트를 위한 자리는 없습니다. (0) | 2022.09.02 |
| "Isolation Forest": 모든 데이터 분석가가 알아야 할 이상 탐지 알고리즘 (0) | 2022.09.02 |




댓글