
분석 엔지니어가 해결해야 할 일반적인 문제
엔지니어는 실제 문제를 해결할 때 최고의 도구를 구축하며, 앞서 언급했듯이 여기에서 해결해야 할 몇 가지 흥미로운 문제가 있습니다. 이 기사에서 해결 방법을 설명하기 위해 최선을 다할 것이며 도움이 되길 바랍니다.
문제 1: 모델 변경 및 테스트
타사 API를 사용하여 데이터를 가져와 데이터베이스에 저장한다고 가정해 보겠습니다. API를 다른 데이터 구조를 가질 가능성이 높은 다른 공급자로 변경해야 하는 상황이 발생합니다. API 공급자를 변경하는 것은 매우 간단할 수 있지만 변경이 분석에서 사용하는 데이터에 부정적인 영향을 미칠지 확신할 수 없습니다. 예를 들어 데이터 모델에 정수와 양수여야 하는 열 연령이 포함되어 있고 평균 연령을 계산하기 위해 해당 열을 기반으로 분석에서 메트릭을 구축했습니다. 새 API 공급자가 버그가 있고 나이를 음수로 반환하는 경우 사람들이 분석에 표시되는 이상한 결과를 보고하기 시작할 때까지 문제를 알아차리지 못할 것입니다. 잘못된 분석으로 인해 다운스트림에서 발생한 오류에 대해 책임을 지지 않습니다.
문제 2: 분석 테스트
소프트웨어 엔지니어링에 대한 탄탄한 배경지식이 있는 사용자는 프로덕션에 적용되는 모든 코드 변경이 적절하게 테스트되어야 한다는 것을 알고 있습니다. 프로덕션과 화난 고객의 치명적인 버그를 원하지 않습니다. 요즘에는 소프트웨어 엔지니어링, 이른바 지속적 통합 및 지속적 전달에 모범 사례가 있습니다. 프로덕션 단계에 있는 모든 코드 변경 사항은 적절하게 테스트되며 올바르게 관리된다면 프로덕션이 중단되지 않습니다. 분석에도 동일한 원칙이 적용됩니다. 노골적으로 깨진 분석을 배포하고 사용자 기반을 좌절시키고 싶지 않습니다. 따라서 분석의 모든 변경 사항을 적절하게 테스트해야 합니다.
문제 3: 분석 배포
데이터 및 분석을 테스트하더라도 고객이나 내부 사용자에게 새로운 분석을 지속적으로 배포해야 합니다. 프로덕션 환경에서 새로운 메트릭과 시각화를 구축하고 싶지 않을 수 있지만 이상적으로는 분석이 준비되면 프로덕션 환경에 모든 것을 한 번에 배포하는 것이 좋습니다. 또한 일반적으로 수동 배포를 원하지 않지만 CI/CD 파이프라인(예:)을 사용합니다. 다시 소프트웨어 엔지니어링 모범 사례를 적용합니다.
분석 엔지니어의 문제에 대한 솔루션
GitLab의 공개 리포지토리에서 확인할 수 있습니다 .
먼저 데이터가 필요했기 때문에 GitHub REST API 를 통해 크롤링하고 (예: GitHub 데이터를 분석하고 팀을 위한 간단한 대시보드를 구축할 수 있음) 데이터를 PostgreSQL 데이터베이스에 로드하는 사용자 지정 스크립트를 작성했습니다. PostgreSQL은 문제에 필수적인 것은 아닙니다. Snowflake 와 같은 다른 솔루션을 사용할 수 있습니다 . 데이터 변환 및 테스트에는 dbt 를 사용했고 분석에는 GoodData 를 사용했습니다 . 언급했듯이 솔루션은 하나의 파이프라인이며 GitLab CI/CD 를 사용하는 것이 완벽 합니다.
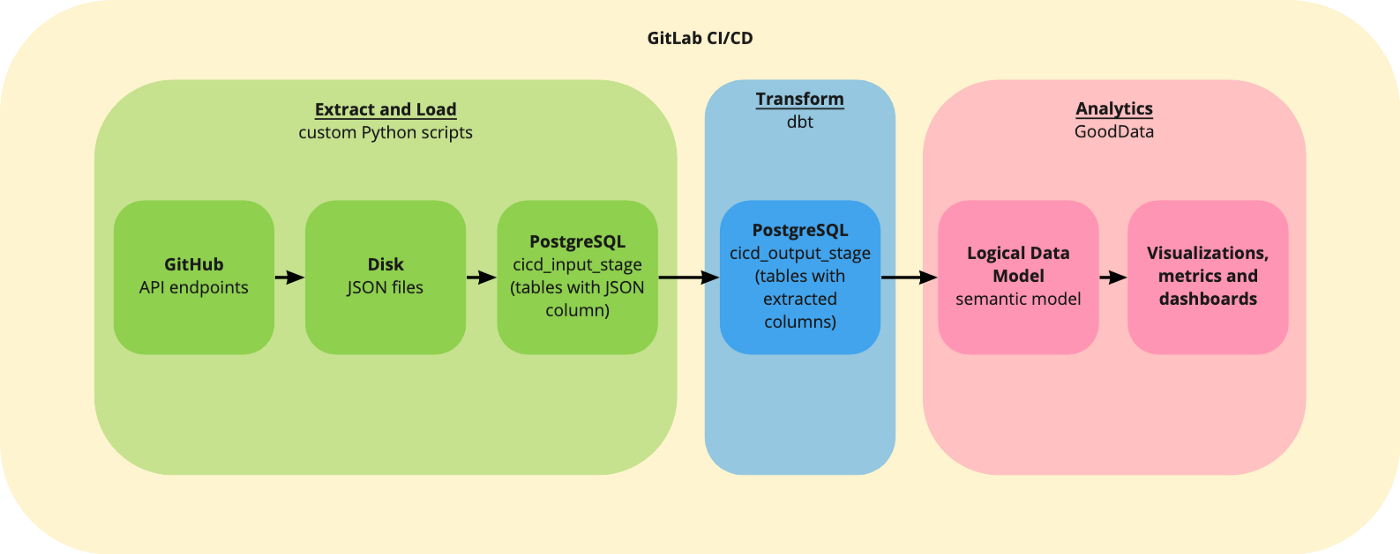
단일 파이프라인 작업에 대해 자세히 알아보기 전에 파이프라인 워크플로에 대해 자세히 설명하겠습니다. 전체 파이프라인에서 병합 전 및 병합 후 단계의 개념을 사용합니다. 누군가가 병합 요청을 생성하면 사전 병합 단계에서 모든 것이 올바르게 작동하는지 확인합니다. 또한 필수 코드 검토(엔지니어링 모범 사례와 일치)가 있습니다. 또한 코드 검토자는 UI의 스테이징 환경에서 결과를 검증할 수 있으며 검토 프로세스가 완료되면 검토자는 병합 요청을 완료할 수 있습니다. 이러한 모든 검사가 통과된 경우에만 새 버전이 프로덕션 환경에 전달됩니다.
추출 및 로드
organization-level우리는 각각에 대해 엔티티(users)를 크롤링하고 로드 organization하며 각각의 각 저장소에 대해 엔티티( , ) organization에 대해 동일한 작업을 수행합니다 . 향후 추가 엔터티로 쉽게 확장할 수 있어야 합니다. 우리는 페이징된 API에서 모든 페이지를 수집합니다. 타임스탬프보다 최신(마지막 업데이트) 행에 대해서만 기본 타임스탬프를 수집합니다. 이는 증분 로드를 위한 준비입니다.
변환
데이터베이스에서 데이터를 변환하려는 경우 dbt는 이 작업을 위한 완벽한 도구입니다. 이것은 T in ETL/ ELT파이프라인을 나타냅니다. 나중에 분석에 연결할 모델을 쉽게 생성할 수 있으며 dbt는 최고의 소프트웨어 엔지니어링 사례를 적용하면서 모든 것을 생성, 테스트 및 문서화하는 데 도움이 됩니다.
해석학
GoodData를 사용하면 코드( GoodData Python SDK) 를 사용하여 액세스할 수 있는 일관된 메트릭 및 대시보드를 만들 수 있습니다 . CI/CD 파이프라인(코드로서의 분석)에 분석을 배포하는 것은 큰 이점입니다. 또한 코드를 사용하여 분석을 관리할 수 있습니다.
파이프라인 구성
GitLab은 빠르고 무료 파이프라인(데모용)을 실행할 수 있는 기본 DevOps 플랫폼입니다. 하나 YAML의 파일을 사용하여 전체 파이프라인을 쉽게 구성할 수 있습니다.
최신 데이터 파이프라인 — 구현
전체 파이프라인은 일련의 Python 및 SQL스크립트(파이프라인 정의에 대해 하나의 파일을 계산하지 않는 경우 YAML)이며 git에서 이러한 스크립트의 버전을 지정할 수 있기 때문에 훌륭합니다. 종단 간 데이터 파이프라인의 단일 버전은 파이프라인의 모든 단계가 일관적이며 모든(일관된) 버전으로 되돌릴 수 있음을 의미합니다. 전체 파이프라인에는 4단계가 있습니다. 불필요한 세부 사항으로 인해 과부하가 걸리지 않도록 가장 중요한 것만 설명하겠습니다. 그러나 세부 사항에 정말로 관심이 있으시면 소스 코드가 있는 저장소를 확인하십시오.
구현에 대해 알아보기 전에: GoodData 분석으로 전체 파이프라인을 구현하려면 분석 을 구축할 GoodData 평가판 계정 을 등록하세요. 등록하지 않으려면 Docker 또는 helm 차트에서 로컬로 배포할 수 있는 GoodData.CN(클라우드 네이티브 버전)으로 시작할 수 있습니다. 자세한 내용은 설명서 를 참조하십시오 .
추출 및 로드
파이프라인의 첫 번째 단계는 GitHub REST API에서 데이터를 추출하고 특정 스키마의 데이터베이스에 저장하는 것입니다 cicd_input_stage.
이야기할 가치가 있는 두 가지 중요한 방법이 있습니다. 일부 설정과 도우미Extract 메서드가 포함된 데이터 추출을 위한 새 클래스를 작성 했지만 가장 중요한 것은 다음과 같은 마법이 발생하는 곳 입니다. 나중에 데이터를 쓰는 메서드를 호출합니다 .JSON
데이터를 사용하면 JSON모든 것을 데이터베이스에 아주 간단하게 로드할 수 있습니다. 우리는 그것을 달성하는 데 도움이 되는 두 개의 새로운 클래스(class Load및 class )를 작성합니다. Postgres단순화를 위해 데이터베이스에 데이터를 로드하는 중요한 작업을 수행하는 방법만 보여드리겠습니다.
구현에 따르면 처음에 한 번만 테이블을 재생성한 다음 각 조직에 대해 각 테이블을 로드합니다. 의 구조 cicd_input_stage는 다음과 같습니다.

보시다시피 각 테이블에는 하나의 JSON열만 있습니다. 각 항목에 대한 자세한 내용을 볼 수 있어야 하므로 분석에 그리 편리하지 않습니다. 다음 단계에서 데이터를 변환합시다!
변환
dbt는 우리의 문제(JSON 열)에 완벽하게 맞습니다 cicd_input_stage. 이 단계의 결과는 cicd_output_stage데이터 모델이 분석을 위해 준비된 입니다(전체 스키마는 이 섹션의 끝에 있음). dbt에서는 SQL파일에 모델을 작성합니다. 모든 모델은 select 문입니다. 예를 들어 테이블 사용자의 데이터를 변환하는 모델은 cicd_input_stage다음과 같습니다.
관심 있는 JSON 속성 의 간단한 스크립트를 볼 수 extracts있지만 최종 테이블(또는 보기 - dbt 프로젝트를 구성하는 방법에 따라 다름)에는 다음과 같은 유형이 포함 되며 COLUMNS분석 목적에 훨씬 더 좋습니다. 분석 목적으로 작동하는 이러한 모델을 여러 개 작성할 수 있으며 모든 버전이 git에서 관리됩니다. 또 다른 이점은 dbt를 아는 모든 사람이 프로젝트를 즉시 이해할 수 있다는 것입니다. dbt의 가장 큰 장점 중 하나는 dbt 프로젝트에 대한 문서를 생성 하고 웹사이트로 렌더링 하는 방법으로 혼란스러운 환경에 질서를 부여한다는 것 입니다. 또한 단순히 모델 테스트를 시작할 수 있다는 점도 언급하겠습니다. 스키마 파일을 정의할 수 있습니다.INTTEXTYAML스키마가 따라야 하는 "규칙"이 포함된 파일입니다. 예를 들어, user_id는 항상 기본 키여야 합니다.
테스트가 간단하다는 것을 알 수 있습니다. 더 복잡한 테스트에 관심이 있다면 dbt 문서 를 확인하는 것이 좋습니다 . 이 단계의 결과는 cicd_output_stage다음과 같은 스키마입니다.
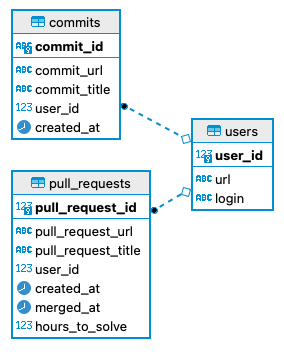
분석 — 스테이징
여기서는 GoodData에서 분석을 생성하는 방법을 설명하지 않겠습니다. GoodData로 작업하는 방법에 대해 자세히 알아보려면 설명서를 확인하는 것이 좋습니다 .
스테이징 분석을 모든 분석을 준비하고 이해 관계자와 상담할 수 있는 테스트 환경으로 이해할 수 있습니다. 분석이 준비되면 프로덕션 환경에 배포할 수 있습니다(다음 섹션에 설명됨).
이전 단계의 결과는 데이터베이스의 cicd_output_stage 스키마였습니다. GoodData를 스키마에 연결하고 의미 모델( GoodData 언어의 Logical Data Model )을 만들고 시각화 및 대시보드를 만들어야 합니다. UI에서 이를 수행하고 언급된 GoodData Python SDK 를 사용하여 관리할 수 있습니다 . 리포지토리 의 폴더 분석 에는 파이프라인의 일부이기도 한 코드를 사용하여 GoodData를 관리하는 방법의 예가 포함되어 있습니다. 이 섹션에서는 가장 흥미로운 부분인 분석 테스트에 대해 설명합니다. 다음에 나오는 스크립트는 GoodData에서 생성된 시각화(통찰이라고도 함)를 테스트하는 것입니다. GoodData에 시각화가 있는 경우 파이프라인의 일부로 다음 스크립트를 실행할 수 있습니다.
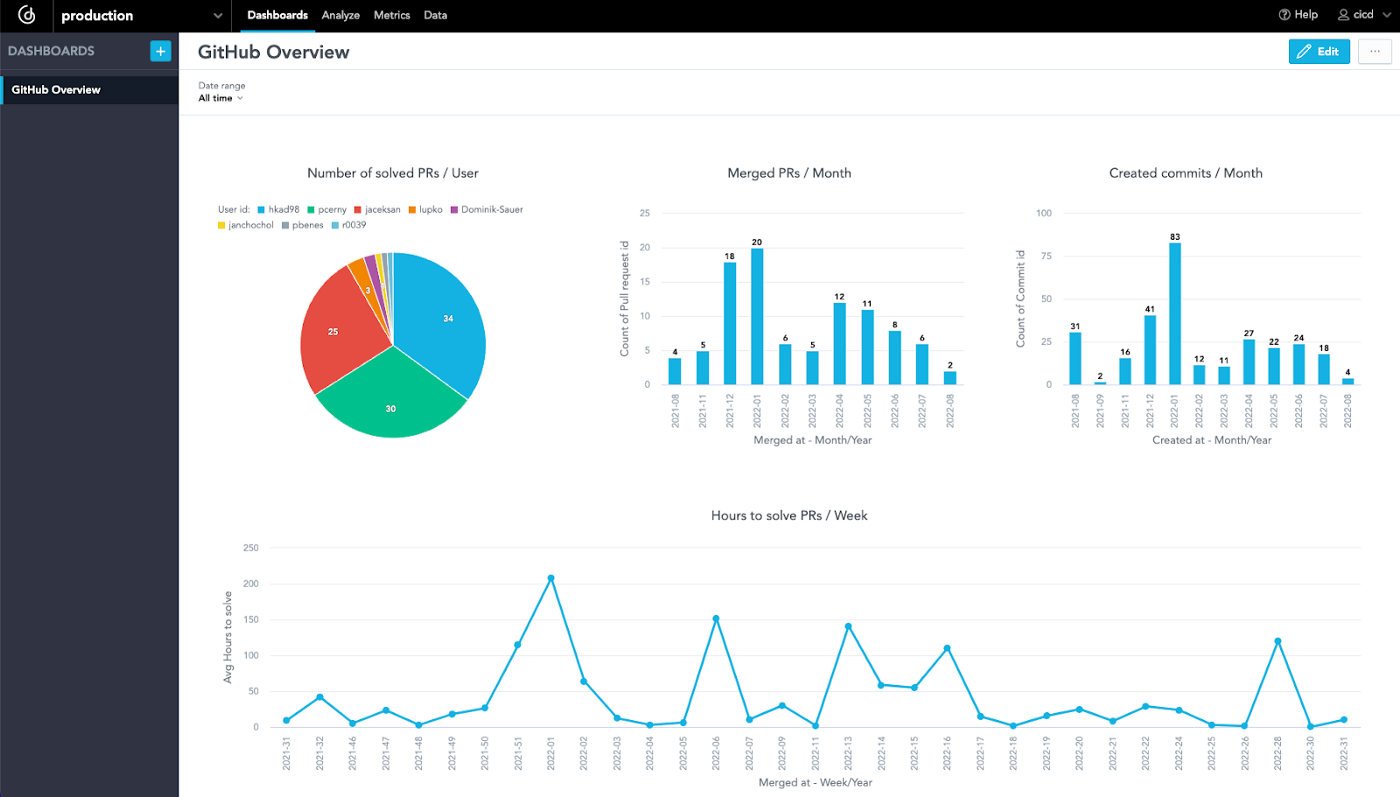
스크립트는 모든 시각화를 실행(또는 계산)할 수 있는지 테스트합니다. 모든 시각화가 실행 가능하다는 것을 알고 있으면 분석이 정확할 가능성이 높기 때문에 프로덕션 환경에 변경 사항을 배포할 수 있는지 확인하는 데 도움이 됩니다. GoodData Python SDK를 사용하면 대시보드에 필요한 모든 시각화 등이 포함된 경우와 같이 이러한 테스트를 여러 개 작성할 수 있습니다. 스크립트에는 GitLab CI/CD 변수 에서 로드되는 환경 변수도 포함됩니다 (파이프라인에서 원하는 경우 로컬로 정의). 이제 스테이징 분석을 사용하여 모든 것을 프로덕션 환경에 배포하기만 하면 됩니다. 계속하기 전에 GoodData에서 분석이 어떻게 보이는지 살펴보겠습니다.
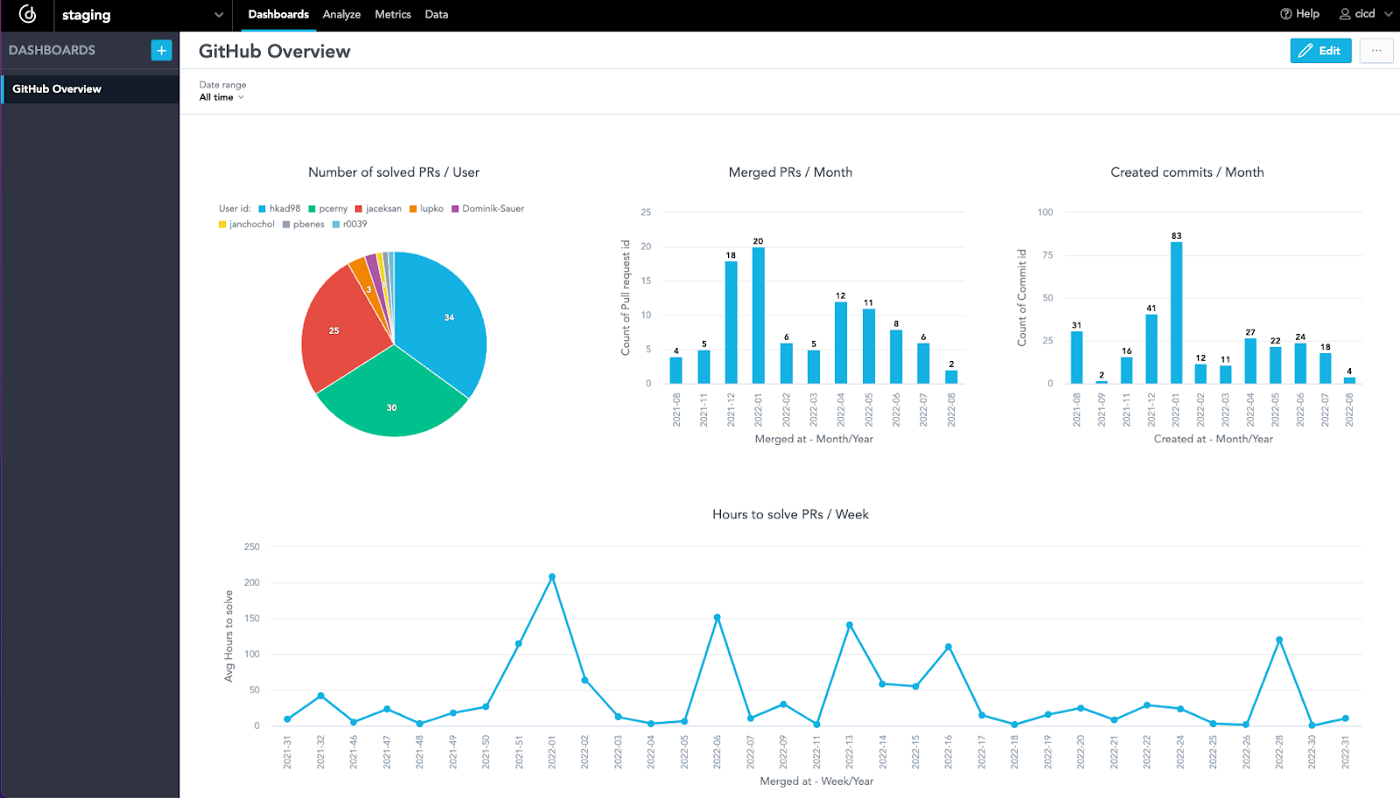
분석 — 생산
이제 스테이징 분석이 준비되었으므로 프로덕션 환경에 모든 것을 배포해야 합니다. GoodData Python SDK 덕분에 몇 줄의 코드만 있으면 됩니다.
스크립트는 두 가지 작업을 수행합니다. 첫째, 스테이징 분석(분석 모델 - 시각화, 메트릭, 대시보드 등)의 모든 것을 복사하고 모든 것을 프로덕션 환경에 넣습니다. 분석이 프로덕션 환경에 있으면 모든 이해 관계자가 사용할 수 있으며 이전의 모든 단계 덕분에 모든 것이 정확하다는 것을 합리적으로 확신할 수 있습니다.
파이프라인 구성
마지막 단계는 GitLab CI/CD에서 전체 파이프라인을 구성하는 것입니다. 전체 파이프라인에는 4단계가 있습니다.
그 중 3개( extract_load, transform, 및 analytics_staging)는 병합 전에 실행됩니다. 예를 들어 GitLab 리포지토리에서 새 병합 요청을 생성하는 경우입니다. 마지막( analytics_prod)은 병합 후 실행됩니다(코드 검토 포함). 첫 번째 단계를 살펴보겠습니다 extract_load.
가장 중요한 것은 모든 종속성을 설치한 다음 데이터 추출 및 로드 섹션에 설명된 두 개의 스크립트를 실행하는 스크립트입니다. 또한 규칙을 볼 수 있습니다. 대상 분기가 기본인 경우 병합 요청에서 실행되거나 GitLab 예약된 파이프라인 덕분에 예약된 단계로 실행할 수 있습니다 . 또한 extract_load폴더를 변경하지 않으면 스테이지가 실행되지 않습니다.
단순화를 위해 전체 파이프라인의 구성을 설명하지는 않겠지만 전체 파이프라인 은 저장소에서 찾을 수 있고 README.md 에서 더 많은 정보를 찾을 수 있습니다 . 한 단계 더 살펴보겠습니다(GoodData — 스테이징에 설명된 스테이징 분석용).
스테이지는 스크립트만 실행하지만 스크립트는 흥미로운 작업을 수행합니다. 데이터 소스 등록으로 시작하여 분석 테스트로 끝납니다. 또한 규칙 덕분에 모든 스크립트가 있는 분석 폴더에서 무언가를 변경하는 경우에만 스테이지가 실행됩니다.
최신 데이터 파이프라인 — 데모
이제 파이프라인이 준비되었으며 작동 방식을 시연할 수 있습니다! 전체 파이프라인을 실행하기 위해 모든 폴더에서 사소한 변경을 수행하는 간단한 병합 요청을 생성하겠습니다. 세부 정보를 보려면 여기 에서 병합 요청을 사용할 수 있습니다. 단일 작업의 세부 정보와 로그를 확인할 수도 있습니다. 병합 요청을 생성하면 파이프라인이 실행되기 시작합니다.
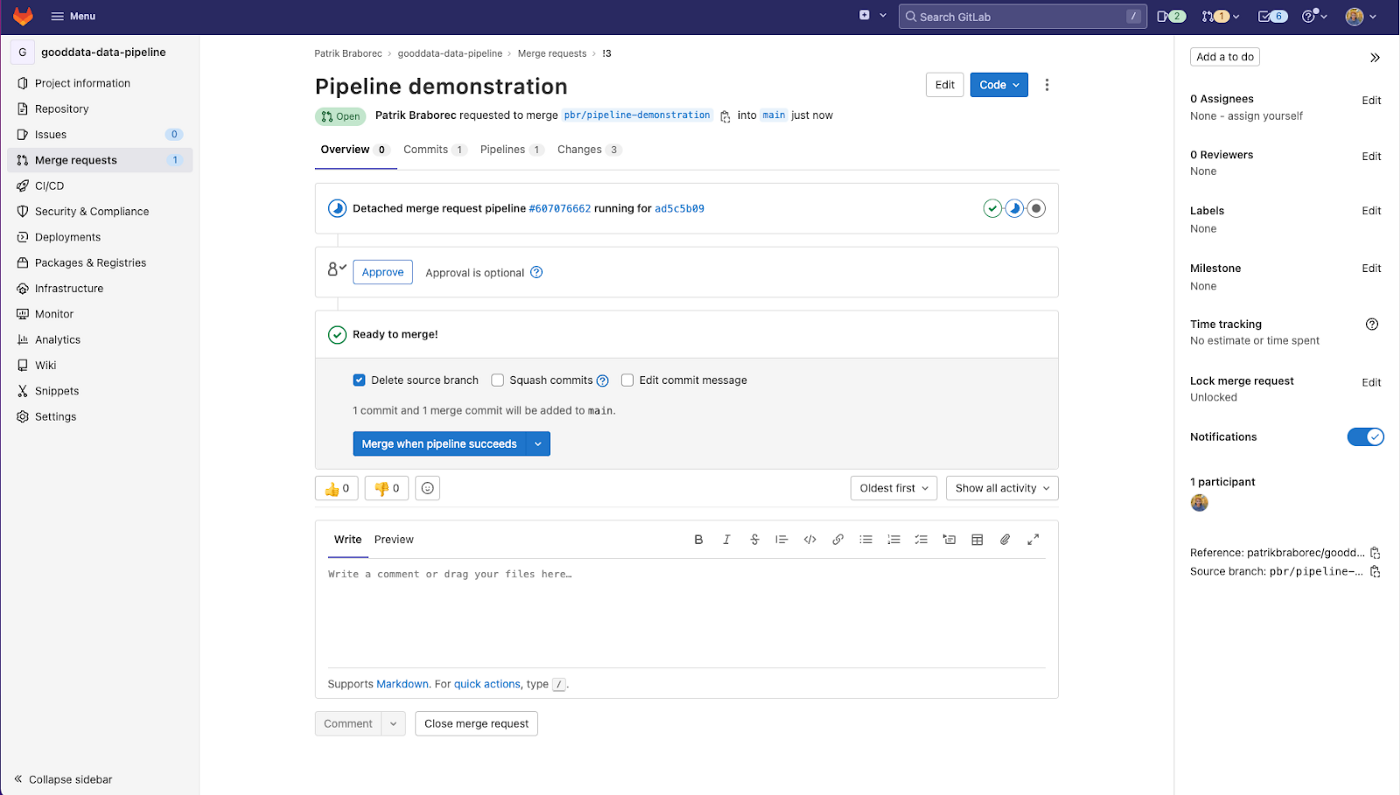
잠시 후 단계 extract_load, transform및 analytics_staging통과:

모든 것을 프로덕션에 배포할 준비가 되면 병합 요청을 병합할 수 있으며 마지막 단계에서 analytics_prod다음이 실행됩니다.

결과는 프로덕션 환경에서 새롭고 테스트된 분석입니다.
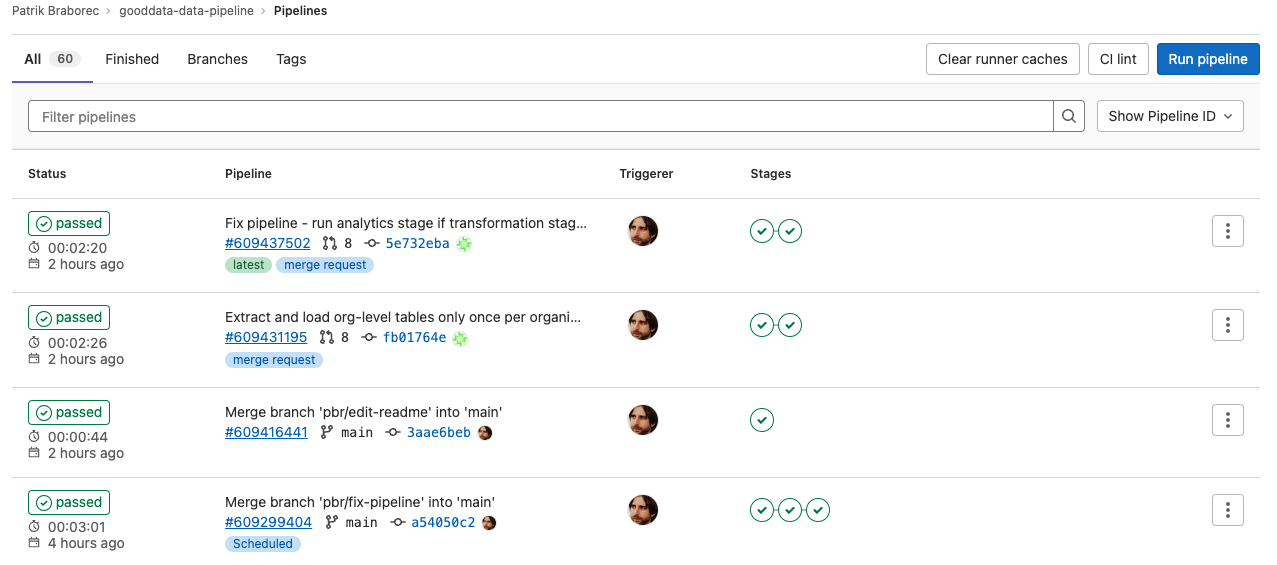
또한 예정된 파이프라인 이전에 언급했듯이 GitLab에서 어떻게 보이는지 확인할 수 있습니다(단, 단계 extract_load및 transform).
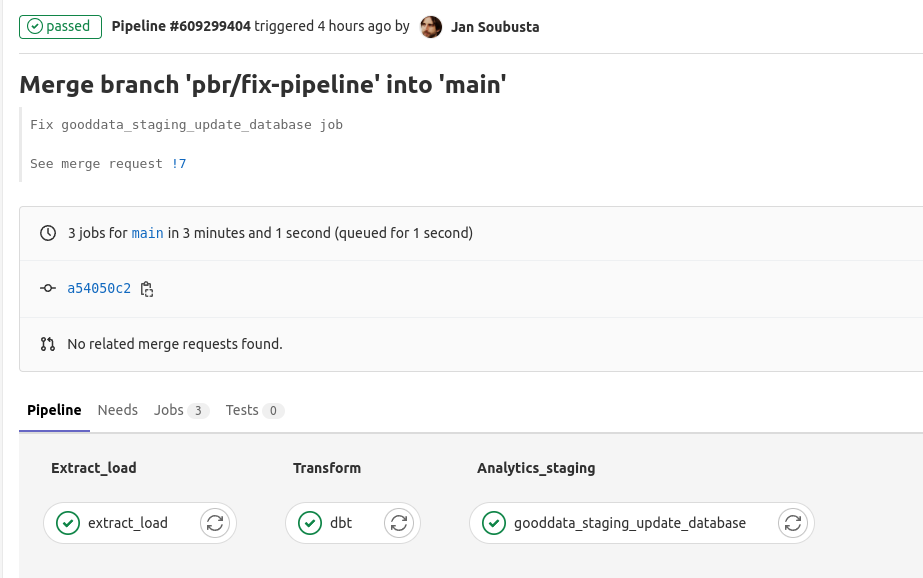
파이프라인의 세부 사항은 다음과 같습니다.
'Daily Review' 카테고리의 다른 글
| An End-to-End Unsupervised Anomaly Detection (0) | 2022.08.30 |
|---|---|
| SQL을 사용한 레스토랑 판매의 탐색적 데이터 분석(EDA) (3) | 2022.08.30 |
| 머신 러닝을 위한 데이터 전처리 (0) | 2022.08.30 |
| 데이터 분석가로서 알아야 할 7가지 SQL 쿼리 (0) | 2022.08.29 |
| 시계열 데이터에 K-평균 클러스터링을 적용하는 방법 (0) | 2022.08.29 |




댓글