
SQL이란 무엇입니까?
Structured Query Language 의 약자인 SQL 은 데이터베이스 시스템 또는 관계형 데이터베이스 관리 시스템과 상호 작용하는 데 사용되는 표준 컴퓨터 언어입니다. 따라서 사용자는 SQL을 사용하여 데이터베이스 시스템에서 데이터를 추가, 수정, 업데이트, 검색 및 삭제할 수 있습니다.
오늘날 우리는 데이터가 얼마나 중요한지 알고 있습니다. 이 게시물에서는 연구 사례와 함께 가장 일반적인 SQL 쿼리를 볼 것입니다.
참고: 모든 쿼리는 https://www.w3schools.com/sql/ 에 작성되었습니다 .
1. 고유 및 집계 함수 선택
1.1 고유 선택
테이블 내부의 열에는 종종 많은 중복 값이 포함됩니다. 때로는 다른(고유한) 값만 나열하고 싶을 수도 있습니다. 중복 데이터를 제거하기 위해 select 독특한 문을 사용할 수 있습니다.
개별 선택 을 사용 하면 동일하거나 중복된 데이터가 제거되고 고유한 데이터만 표시됩니다.
구문:
SELECT DISTINCT column1, column2,...
FROM table_name;
1.2 집계 함수
집계 함수는 값 그룹에 대한 계산을 수행하는 데 사용됩니다. sum(), count(), avg(), max() 및 min() 과 같은 다양한 집계 함수 는 다음과 같습니다.
min() 함수 는 선택한 열의 가장 작은 값을 반환합니다.
max() 함수 는 선택한 열의 가장 큰 값을 반환합니다.
count() 함수 는 지정된 기준과 일치하는 행 수를 반환합니다.
avg() 함수 는 숫자 열의 평균 값을 반환합니다.
sum() 함수 는 숫자 열의 총합을 반환합니다.
구문:
SELECT '집계 함수'(column_name)
FROM table_name;
데모 데이터베이스
전자 상거래의 판매 데이터를 포함하는 2개의 테이블이 있다고 가정해 보겠습니다. 저는 이를 ecommerce_event 및 user_profile 테이블이라고 부릅니다.
다음은 ecommerce_event 테이블의 내용이며,
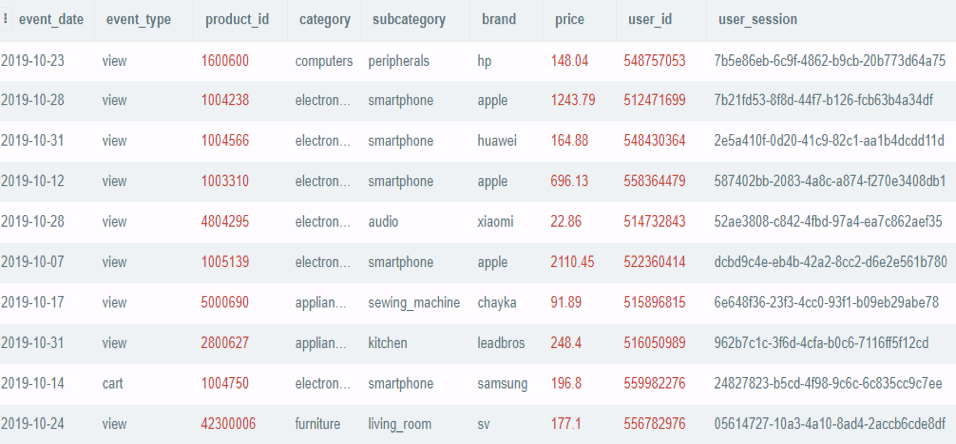
이 테이블은 날짜 정보와 함께 사용자가 수행한 이벤트의 기록 및 제품 정보를 포함합니다.
그러면 다음은 사용자 정보에 대한 기록을 담고 있는 user_profile 테이블의 내용이다.
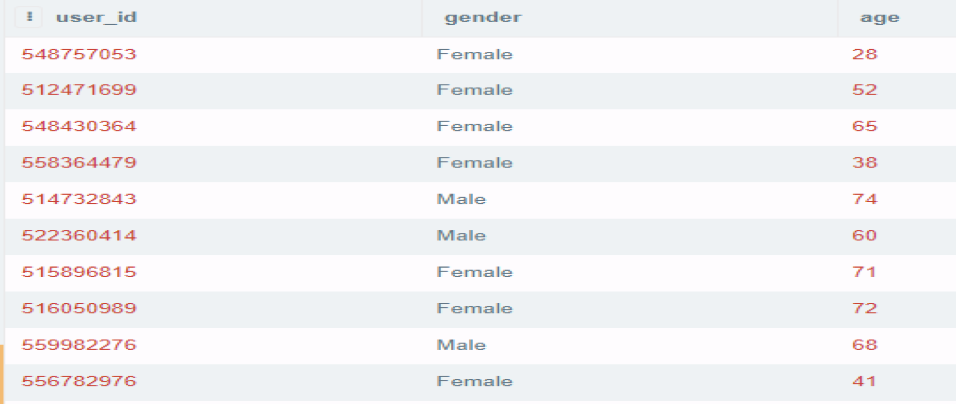
이제 판매 정보를 얻기 위해 이 두 테이블을 탐색해 보겠습니다!
실시예 1
"ecommerc_event " 테이블에서 출력할 SQL 쿼리를 작성합니다.
1. user_session의 총 고유
2. 최저, 최고, 평균 가격
"event_type"이라는 기준 으로 애플과 삼성을 제외한 뷰와 브랜드입니다.
이에 대한 답을 하기 전에 우리가 정말로 주의를 기울여야 할 문제를 분석해 보겠습니다.
a. user_session 및 price 열인 데이터를 표시하는 데 필요한 열을 선택합니다.
b. 열에는 종종 많은 중복 값이 포함되어 있으므로 user_session 열에 count 고유한 문을 사용하여 고유한 데이터의 양을 얻을 수 있습니다.
c. b 지점에서 출력을 얻으려면 avg(), max() 및 min() 함수 를 사용하여 price 열의 값을 집계할 수 있습니다 .
d. 그런 다음 요청된 기준에 따라 where 절을 사용하여 데이터를 필터링합니다 .
쿼리:
SELECT
COUNT(DISTINCT user_session) AS total_unique_user_session,
MIN(price) AS lowest_price,
MAX(price) AS highest_price,
ROUND(AVG(price),2) AS average_price
FROM
ecommerce_event
WHERE
event_type = 'view' AND brand NOT IN('apple' ,'samsung');
결과 :

따라서 2019년 10월 전체의 결과는 12,550 세션이었고, 그 다음으로 최저 가격 0.88, 최고 가격 2,574.07, 평균 가격 246.25였습니다.
2. Where 절
절은 레코드를 필터링하는 데 사용됩니다 . 지정된 조건을 충족하는 레코드만 추출하는 데 사용됩니다.
구문:
SELECT DISTINCT column1,column2,..
FROM table_name
WHERE 조건;
실시예 2
총 고유 제품을 출력하는 SQL 쿼리를 작성하십시오. 'a' 또는 'k' 문자로 시작하고 날짜가 '2019–10–04' 이후인 필터 브랜드 문제를 분석해 보겠습니다. 먼저 제품의 고유 번호를 표시해야 합니다. 따라서 product_id 열에 count 고유한 문을 사용하고 where 절을 사용하여 일부 기준을 필터링할 수 있습니다.
쿼리:
SELECT
COUNT(DISTINCT product_id) as total_product
FROM
ecommerce_event
WHERE (brand LIKE 'a%' OR brand LIKE 'k%')
AND event_date > '2019-10-04';
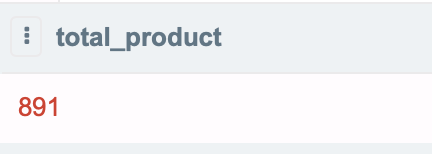
그리고 그 결과 2019년 10월의 총 고유 제품은 891개에 달했습니다.
3. 조항별 그룹화 및 정렬
SQL에서 데이터를 그룹화하기 위해 group by 문을 사용합니다. group by 문은 값이 같은 데이터를 하나 의 그룹으로 그룹화하고 (COUNT, MAX, MIN, SUM, AVG)와 같은 집계 함수를 사용하여 구성된 각 그룹 또는 그룹에 대한 집계를 수행할 수 있습니다. while order by키워드는 결과 집합을 오름차순 또는 내림차순으로 정렬하는 데 사용됩니다.
주의해야 할 중요한 사항은 다음과 같습니다.
a. Group by 는 select 와 함께 사용되며 group by 문 에서 사용되는 열도 select 에 배치되어야 함을 의미합니다 .
b. Group by 는 where 다음에 배치되지만, where 를 사용하지 않으면 from 바로 뒤에 배치 됩니다 .
c. order by 를 사용하는 경우 group by 는 order by 보다 먼저 배치 됩니다.
구문:
SELECT column_name(s)
FROM table_name
WHERE 조건
GROUP BY column_name(s)
ORDER BY column_name(s);
실시예 3
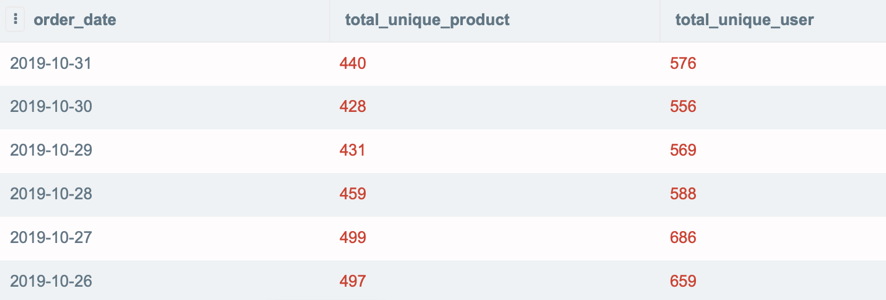
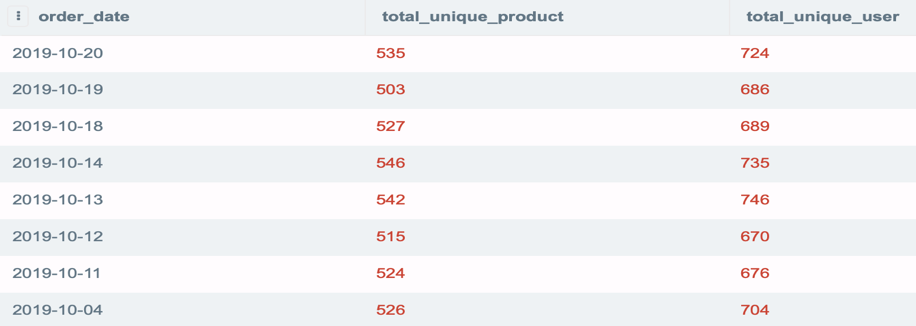
모든 주문 날짜에 대해 총 고유 제품 및 총 고유 사용자 를 출력하는 SQL 쿼리를 작성하십시오 . 2019년 8월 4일 이후의 날짜만 표시하고 가장 늦은 날짜로 결과를 정렬합니다.
이 경우 고유 번호를 얻기 위해 product_id 및 user_id 열에 count 고유한 문을 사용해야 하고 동일한 값을 가진 행을 요약 행으로 그룹화 하는 group by 문도 사용해야 합니다.
쿼리:
SELECT
event_date AS order_date,
COUNT(DISTINCT product_id) AS total_unique_product,
COUNT(DISTINCT user_id) AS total_uniques_user
FROM
ecommerce_event
WHERE
order_date > '2019-08-04'
GROUP BY order_date
ORDER BY order_Date DESC;
결과 :
4. Having 절
데이터를 집계 하는 그룹을 사용할 때 where 대신 have 절을 사용합니다.
구문:
SELECT column_name(s)
FROM table_name
WHERE 조건
GROUP BY column_name(s)
HAVING 조건
ORDER BY column_name(s);
실시예 4
예제 3의 질문에서 총 고유 제품이 500개를 초과하는 날짜만 필터링합니다.
이전과 유사하게 이 경우 집계 데이터에 have 절만 추가 하면 됩니다.
쿼리:
SELECT
event_date AS order_date,
COUNT(DISTINCT product_id) AS total_unique_product,
COUNT(DISTINCT user_id) AS total_uniques_user
FROM
ecommerce_event
WHERE
order_date > '2019-08-04'
GROUP BY order_date
HAVING total_unique_Date > 500
;
결과 :
5. Join
조인 절은 데이터베이스에 있는 둘 이상의 서로 다른 테이블을 조인하는 것입니다 . 이 조인 은 테이블에 동일한 열 키가 있는 경우에만 수행할 수 있습니다. SQL에는 내부 조인 , 왼쪽 조인 또는 오른쪽 조인 과 같은 여러 유형의 조인 이 있습니다. 조인 유형마다 목적과 쿼리 결과가 다릅니다.
구문:
SELECT column_name(s)
FROM table1
JOIN table2
ON table1.column_name = table2.column_name ;
실시예 5
ecommerc_event 및 user_profile 테이블에서 2019년 10월에 세션이 더 많은 성별은 무엇입니까?
잠시만요. 이 경우 2019년 10월 동안 가장 많은 세션이 발생한 성별에 대한 정보를 얻기 위해 2개의 테이블을 결합해야 합니다. 먼저 각 테이블의 기본 키와 외래 키를 찾아야 합니다. 이 키는 테이블 정보를 얻을 수 있도록 두 테이블을 연결하는 데 유용합니다.
ecommerce_event 테이블의 user_id 열은 user_profile 테이블의 user_id 열을 참조합니다. 따라서 위의 두 테이블 간의 관계는 user_id 열입니다.
그런 다음 두 테이블에서 일치하는 값을 가진 레코드를 선택하는 내부 조인을 사용하여 다음 SQL 문을 만들 수 있습니다.
쿼리:
SELECT
gender,
COUNT(DISTINCT user_session) as total_sessions
FROM
ecommerce_event as e
INNER JOIN user_profile as u
ON e.user_id = u.user_id
WHERE
event_date BETWEEN '2019-10-01' AND '2019-10-30'
GROUP BY gender
OR total_sessions DESC;
결과 :

2019년 10월 내내 볼 수 있듯이 남성은 여성보다 세션이 더 많으며 총 세션은 9747입니다.
6. CASE
문 은 case조건을 통과하고 첫 번째 조건이 충족될 때 값을 반환합니다(if-then-else 문과 같이). 따라서 조건이 true이면 읽기를 중지하고 결과를 반환합니다. 조건이 참이 아니면 else절의 값을 반환합니다. 부분 이 else없고 조건이 참이면 null을 반환합니다.
구문:
CASE
WHEN 조건 1 THEN 결과1
WHEN 조건 2 THEN 결과 2
WHEN 조건 N THEN 결과 N
ELSE 결과
END;
실시예 6
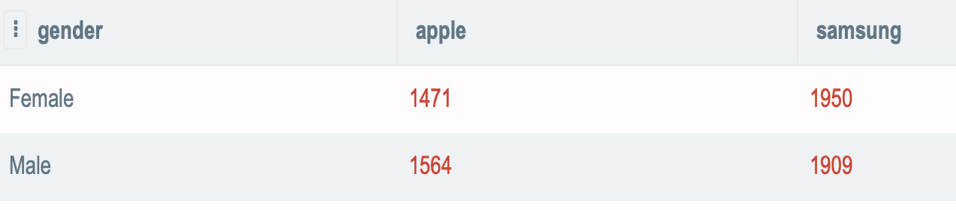
ecommerce_event 및 user_profile 테이블에서 iPhone은 여성이 더 많이, 삼성은 남성이 더 많다는 것이 사실입니까?
case 문 은 다른 열의 값에 따라 한 열의 값을 설정하려는 논리를 구현하는 데 사용됩니다. 이 경우, 우리는 어떤 브랜드(iphone, Samsung)가 성별에 의해 더 지배적인지 알고 싶습니다. 그래서 우리는 case문장이 '브랜드' 조건을 거치고 조건이 참이면 결과를 반환하도록 설정했습니다. 다음은 코드입니다.
쿼리:
SELECT
gender,
COUNT(DISTINCT CASE WHEN brand = 'apple' THEN e.user_id END) AS apple,
COUNT(DISTINCT CASE WHEN brand = 'samsung' THEN e.user_id END) AS samsung
FROM
ecommerce_event AS e
INNER JOIN user_profile AS u
ON e.user_id = e.user_id
GROUP BY gender;
결과 :
7. 서브쿼리
하위 쿼리는 더 큰 쿼리 안에 중첩된 SQL 쿼리입니다. 하위 쿼리는 다음에서 발생할 수 있습니다.
SELECT 절
FROM 절
WHERE 절
실시예 7
수익이 3000 이상인 날짜의 사용자당 일일 평균 수익(수익/사용자 수)을 계산합니다.
문제를 해결하기 위해서는 두 가지 쿼리가 필요합니다.
한 쿼리는 수익과 총 고유 사용자를 반환하고
두 번째 쿼리는 사용자당 일일 평균 수익을 식별합니다.
첫 번째 쿼리:
SELECT
DATE(event_date) AS data_date,
ROUND(SUM(price),2) AS revenue,
COUNT(DISTINCT e.user_id) AS unique_user
FROM
ecommerce_event AS e
INNER JOIN user_profile AS u
ON e.user_id = u.user_id
WHERE event_type = 'buy'
GROUP BY data_date
ORDER BY data_date;
쿼리 결과:
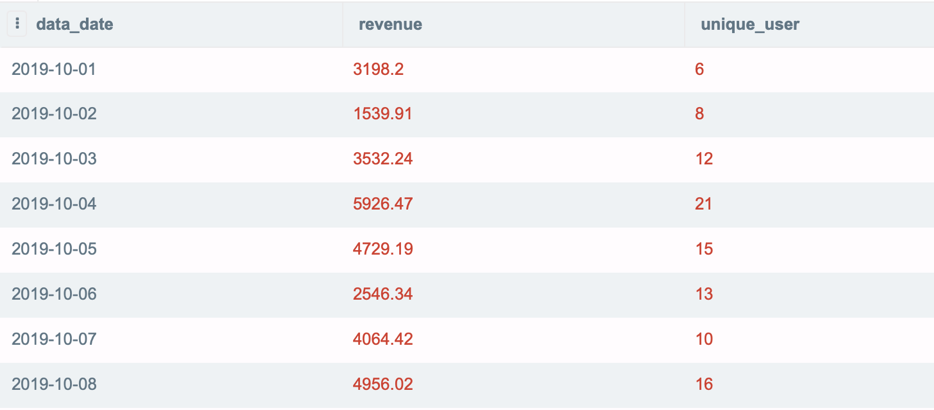
이 쿼리의 결과를 사용하여 수익이 3000보다 큰 날짜에 대한 사용자당 일일 평균 수익을 식별하는 또 다른 쿼리를 작성했습니다. 또는 하나의 쿼리를 다른 쿼리 안에 배치하여 위의 두 쿼리를 결합할 수 있습니다. 하위 쿼리('내부 쿼리'라고도 함)는 괄호 안의 쿼리입니다. 다음 코드 및 쿼리 결과를 참조하십시오.
WITH daily_data AS(
SELECT
DATE(event_date) AS data_date,
ROUND(SUM(price),2) AS revenue,
COUNT(DISTINCT e.user_id) AS unique_user
FROM
ecommerce_event AS e
INNER JOIN user_profile AS u
ON e.user_id = u.user_id
WHERE event_type = 'buy'
GROUP BY data_date
ORDER BY data_date
)
SELECT
data_date,
ROUND(revenue/unique_user, 2) ARPU
FROM
daily_data
WHERE
revenue > 3000;
최종 결과 :

데이터 전문가가 일반적으로 사용하는 쿼리입니다.
도움이 되셨기를 바랍니다! 읽어 주셔서 감사합니다!
'Daily Review' 카테고리의 다른 글
| An End-to-End Unsupervised Anomaly Detection (0) | 2022.08.30 |
|---|---|
| SQL을 사용한 레스토랑 판매의 탐색적 데이터 분석(EDA) (3) | 2022.08.30 |
| 머신 러닝을 위한 데이터 전처리 (0) | 2022.08.30 |
| 최신 데이터 파이프라인을 구축하는 방법 (0) | 2022.08.29 |
| 시계열 데이터에 K-평균 클러스터링을 적용하는 방법 (0) | 2022.08.29 |




댓글