데이터 중심 조직을 향한 발걸음
매일 우리는 전 세계적으로 약 2500조 바이트의 데이터를 생성합니다. 모든 조직은 데이터 중심이 되고 데이터 중심 의사 결정을 내리기를 원합니다. 약 11가지 유형의 데이터베이스 와 100개 이상의 데이터베이스가 있습니다.
조직에는 사용하거나 기반으로 하는 하나 이상의 제품이 있습니다. 제품에는 여러 기능이 있으며 기능의 사용 사례와 데이터 구조 및 모델링 요구 사항에 따라 하나 이상의 데이터베이스를 사용할 수 있으며 다중 언어 및 마이크로서비스 아키텍처도 이를 달성하는 데 도움이 됩니다. 그러나 조직에서 사용하는 여러 데이터베이스(하나 이상의 유형)에 대한 다양성이 증가함에 따라 이를 하나의 우산 아래 통합 관리하고 유지해야 하는 높은 책임도 따릅니다.
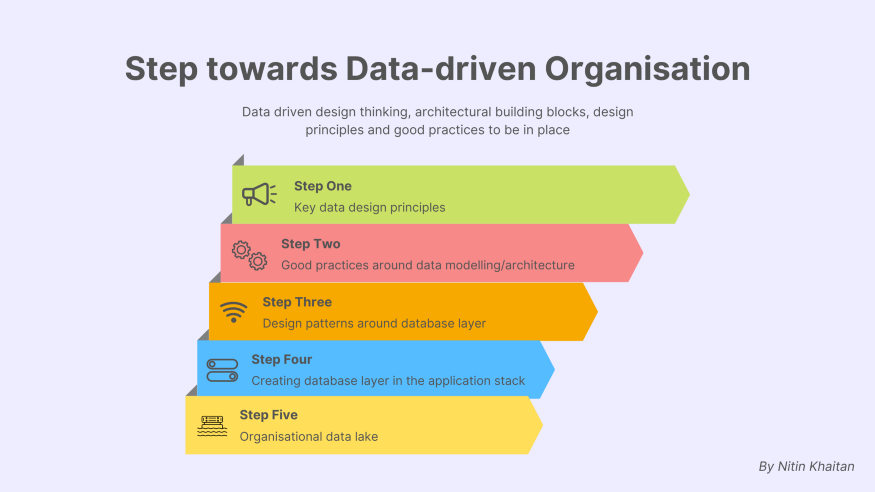
단순히 많은 양의 데이터를 생성하는 조직에서 중앙 집중식 데이터 레이크를 생성 및 의존하고 현재와 미래의 비전을 만족시키는 데이터 신성성을 유지할 수 있는 조직으로 이동하는 경로는 그리 쉽지 않습니다. 이를 위해서는 많은 디자인 사고, 아키텍처 빌딩 블록 , 디자인 원칙 및 모범 사례가 필요합니다. 몇 가지는 아래와 같습니다.
주요 데이터 설계 원칙
공유 자산
데이터는 부서가 아닌 조직에 속합니다. 데이터는 조직적 의미를 따라야 하며 부서 수준이 아니어야 합니다.
데이터 공유 인터페이스
데이터 생성 및 공유는 일부 표준화된 인터페이스 또는 API를 통해 노출되어야 합니다. 직접적인 데이터베이스 상호작용은 금지되어야 하며 이는 보안 규정에도 부합하지 않습니다.
누가 무엇에 액세스할 수 있습니까?
모든 데이터 인터페이스가 모든 사람에게 노출되어서는 안 됩니다. 사용자가 속한 역할 및 그룹의 관점에서 제어해야 합니다.
명명 규칙 및 어휘
데이터 모델링에 대한 명명 규칙 및 모범 사례는 조직 수준에서 정의되어야 하며 데이터 모델링을 수행하는 모든 부서/제품/기능은 이를 따라야 합니다. 일반적인 용어를 사용해야 합니다. ie — 한 부서가 고객 과 다른 소비자 가 옳지 않다고 말합니다. 데이터 가독성과 일관성을 보장하기 위해 공통 어휘를 따라야 합니다.
데이터 큐레이션
요구 사항이 증가함에 따라 새로운 기능이 계속 개발되고 이 여정에서 특정 엔터티에 대한 데이터 정의가 변경될 수 있습니다. 데이터 모델을 반복적으로 살펴보고 필요에 따라 리모델링 또는 데이터 정리를 수행하는 것도 마찬가지로 중요합니다. 도메인 데이터 모델을 그대로 유지하고 비즈니스 요구 사항에 맞게 유지하는 데 도움이 됩니다.
데이터 저장소
다양한 요구 사항과 다양한 마이크로 서비스와 관련하여 여러 데이터베이스 유형과 엔진 및 인스턴스를 보유할 수 있지만 모두 조직 지침 및 규칙에 따라 관리되어야 합니다. 데이터 중복성을 피해야 하며 하나의 목적을 위한 하나의 영구 데이터 저장소를 보장해야 합니다. 데이터 요구 사항의 경우 데이터를 로컬로 복사하여 사용하는 대신 동일한 저장소를 참조해야 합니다.
데이터 모델링/아키텍처에 대한 모범 사례
TOGAF의 BDAT
BDAT는 TOGAF 아키텍처에서 B 비즈니스 , 데이터 , 애플리케이션 및 기술 을 의미합니다. 비즈니스 문제를 해결하는 동안 먼저 비즈니스/도메인 관점에서 생각한 다음 데이터 관점에서 생각해야 합니다. 나중 단계에서 데이터 모델을 변경하는 것은 비용이 너무 많이 들고 위험도 높습니다.
데이터세트 및 데이터 항목 정의
데이터 세트와 해당 데이터 엔티티를 설계하면 다음을 결정하는 데 도움이 됩니다.
- 인터페이스의 데이터 구조
- 어떤 데이터베이스를 사용할 것인가? 즉 — MongoDB와 같은 문서 데이터베이스는 MySql과 같은 RDMS 데이터베이스와 비교할 때 카탈로그에 대한 좋은 사용 사례일 수 있습니다.
데이터 사전
데이터 모델 주변의 메타데이터를 유지하려면 데이터 사전을 만들어야 합니다. 이는 테이블/문서 및 열에 대한 세부 정보를 정의하는 데 도움이 됩니다. 비즈니스 및 일반 사용자의 관점에서 테이블/문서/필드의 목적을 유지하는 데 사용됩니다.
데이터 유효성 검사
대부분 비즈니스 검증은 서비스/비즈니스 계층에서 수행되고 데이터 검증은 애플리케이션의 컨트롤러 계층에서 수행됩니다. 그러나 데이터 신성함의 관점에서 (외래 키, 기본 키 및 고유 키)와 같은 키 제약 조건은 데이터베이스 계층에도 적용되어야 합니다. 이와 함께 문자열 길이, 열거형 및 데이터 유형과 같은 제약 조건도 열 수준에서 적용되어 우수한 데이터 품질을 보장합니다.
누가 언제 무엇을 생성/업데이트했는지
프로덕션 환경에서 데이터베이스 클라이언트를 통한 직접적인 데이터베이스 변경은 절대 해서는 안 됩니다. 항상 비즈니스/서비스 및 저장소 계층을 통해 수행되어야 합니다. 저장소 계층에는 테이블/문서에 자동으로 적용되는 자동 인식 후크가 있어야 합니다.
- created_on
- created_by
- updated_on
- updated_by
ER 다이어그램
이것은 데이터베이스/컬렉션의 다양한 테이블/문서에 대한 시각적이고 직관적인 보기를 제공하며 이러한 테이블/문서가 서로 어떻게 관련되어 있는지 시각화하는 데 도움이 됩니다. 다른 데이터베이스 클라이언트는 기본 데이터베이스에서 ER 다이어그램을 리버스 엔지니어링하기 위해 다른 도구를 제공합니다.
결론
데이터 모델링과 관련된 데이터 설계 원칙 및 관련 모범 사례는 진정한 의미에서 데이터 중심 조직이 되기 위한 열쇠입니다. 이는 진정한 의미에서 소프트웨어 아키텍처 가 개발 목적을 달성할 수 있도록 권한을 부여합니다.
'Daily Review' 카테고리의 다른 글
| "Isolation Forest": 모든 데이터 분석가가 알아야 할 이상 탐지 알고리즘 (0) | 2022.09.02 |
|---|---|
| 데이터사이언티스트에게 필요한 3가지 이상 탐지 모델(Anomaly Detection) (0) | 2022.09.01 |
| LSTM AE를 활용한 이상 탐지 프로젝트 (0) | 2022.09.01 |
| Autoencoder를 활용한 이미지 이상 탐지 (0) | 2022.08.31 |
| 데이터 사이언티스트가 꼭 알아야 하는 '통계적 가설 검증법' 1가지. (0) | 2022.08.31 |




댓글