
소개
우리 중 많은 사람들이 클라우드 데이터 웨어하우스 내에서 컴퓨팅을 중앙 집중화함으로써 제공되는 속도와 효율성의 핵심 능력을 경험했습니다. 이것이 사실이지만 우리 중 많은 사람들은 다른 것과 마찬가지로 이 가치에도 나름의 단점이 있다는 것을 깨달았습니다.
이 접근 방식의 주요 단점 중 하나는 다른 언어, 특히 SQL로 쿼리를 배우고 실행해야 한다는 것입니다. SQL을 작성하는 것이 Python을 실행하기 위해 보조 인프라를 구축하는 것(노트북 또는 사무실 서버에서)보다 빠르고 저렴하지만 데이터 분석가가 클라우드 웨어하우스에서 추출하려는 정보에 따라 다양한 복잡성이 따릅니다. 클라우드 데이터 웨어하우스로 전환하면 Python에 비해 복잡한 SQL의 활용도가 높아집니다. 이 경험을 통해 SQL에서 배우고 수행하는 데 가장 고통스러운 특정 변환을 기록하고 독자에게 이러한 고통을 완화하는 데 필요한 실제 SQL을 제공하기로 결정했습니다.
작업 흐름을 돕기 위해 변환이 실행되기 전후에 데이터 구조의 예를 제공하므로 작업을 따르고 검증할 수 있습니다. 또한 가장 어려운 5가지 변환을 각각 수행하는 데 필요한 실제 SQL도 제공했습니다. 데이터가 변경됨에 따라 여러 프로젝트에서 변환을 수행하려면 새 SQL이 필요합니다. 필요에 따라 분석에 필요한 SQL을 계속 캡처할 수 있도록 각 변환에 대해 동적 SQL에 대한 링크를 제공했습니다!
Datespine
날짜 척추라는 용어가 어디에서 유래했는지는 분명하지 않지만, 그 용어를 모르는 사람들도 아마도 그것이 무엇인지 알고 있을 것입니다. 일일 판매 데이터를 분석하고 다음과 같다고 상상해 보십시오.
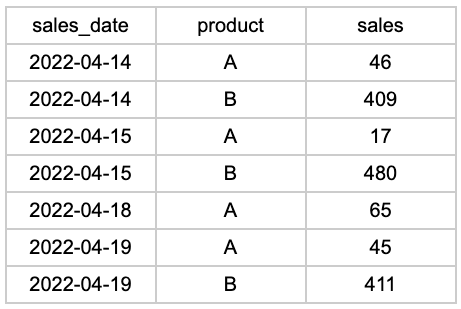
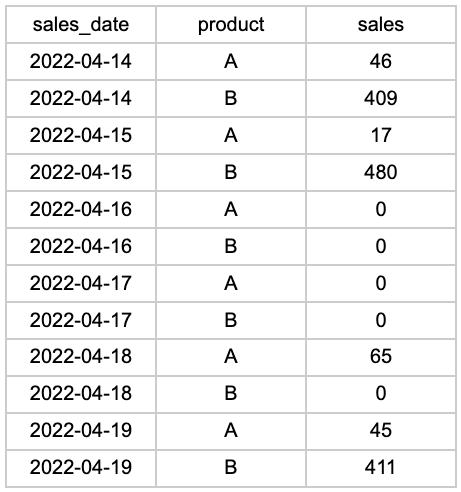
16일과 17일에는 판매가 발생하지 않았으므로 행이 완전히 누락되었습니다. 평균 일일 매출 을 계산 하거나 시계열 예측 모델을 구축하려는 경우 이 형식이 큰 문제가 될 것입니다. 우리가 해야 할 일은 누락된 날짜에 대한 행을 삽입하는 것입니다.
다음은 기본 개념입니다.
- 고유한 날짜 생성 또는 선택
- 고유한 제품 생성 또는 선택
- 교차 조인(데카르트 곱) 1&2의 모든 조합
- 원본 데이터에 대한 외부 조인 #3
WITH GLOBAL_SPINE AS (
SELECT
ROW_NUMBER() OVER (
ORDER BY
NULL
) as INTERVAL_ID,
DATEADD(
'day',
(INTERVAL_ID - 1),
'2020-01-01T00:00' :: timestamp_ntz
) as SPINE_START,
DATEADD(
'day', INTERVAL_ID, '2020-01-01T00:00' :: timestamp_ntz
) as SPINE_END
FROM
TABLE (
GENERATOR(ROWCOUNT => 1097)
)
),
GROUPS AS (
SELECT
product,
MIN(sales_date) AS LOCAL_START,
MAX(sales_date) AS LOCAL_END
FROM
My_First_Table
GROUP BY
product
),
GROUP_SPINE AS (
SELECT
product,
SPINE_START AS GROUP_START,
SPINE_END AS GROUP_END
FROM
GROUPS G CROSS
JOIN LATERAL (
SELECT
SPINE_START,
SPINE_END
FROM
GLOBAL_SPINE S
WHERE
S.SPINE_START >= G.LOCAL_START
)
)
SELECT
G.product AS GROUP_BY_product,
GROUP_START,
GROUP_END,
T.*
FROM
GROUP_SPINE G
LEFT JOIN My_First_Table T ON sales_date >= G.GROUP_START
AND sales_date < G.GROUP_END
AND G.product = T.product;
최종 결과는 다음과 같습니다.
피벗
때때로 분석을 수행할 때 테이블을 재구성하고 싶을 때가 있습니다. 예를 들어 학생, 과목 및 성적 목록이 있지만 과목을 각 열로 나누고 싶습니다. 우리 모두는 피벗 테이블 때문에 Excel을 알고 사랑합니다. 그러나 SQL에서 시도한 적이 있습니까? 모든 데이터베이스는 PIVOT 지원 방식에 있어 성가신 차이가 있을 뿐만 아니라 구문이 직관적이지 않고 쉽게 잊어버릴 수 있습니다.
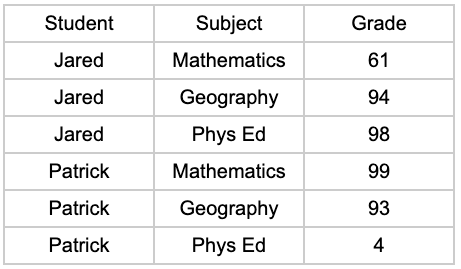
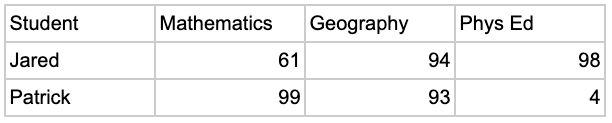
SELECT Student, MATHEMATICS, GEOGRAPHY, PHYS_ED
FROM ( SELECT Student, Grade, Subject FROM skool)
PIVOT ( AVG ( Grade ) FOR Subject IN ( 'Mathematics', 'Geography', 'Phys Ed' ) ) as p
( Student, MATHEMATICS, GEOGRAPHY, PHYS_ED );결과:
원-핫 인코딩(또는 "더미" 변수)
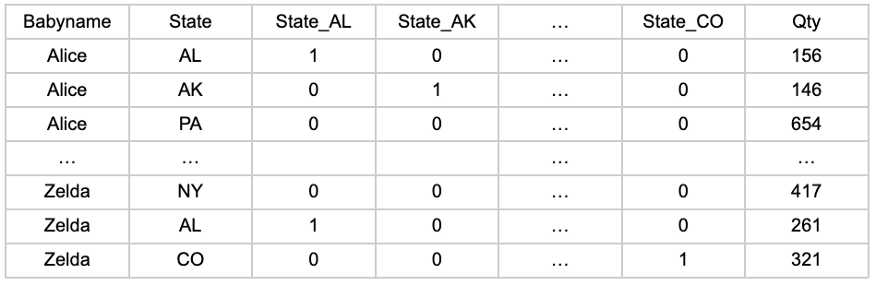
이것은 반드시 어려운 것은 아니지만 시간이 많이 걸립니다. 대부분의 데이터 과학자는 SQL에서 원 핫 인코딩을 고려하지 않습니다. 구문은 간단하지만 26줄 CASE 문을 작성하는 지루한 작업보다 데이터 웨어하우스 외부로 데이터를 전송합니다. 우리는 그들을 비난하지 않습니다!
그러나 데이터 웨어하우스와 처리 능력을 활용하는 것이 좋습니다. 다음은 STATE를 원 핫 인코딩할 열로 사용하는 예입니다.
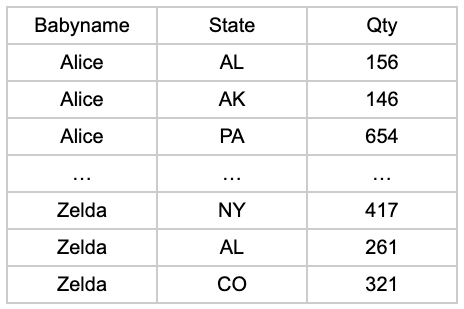
SELECT *,
CASE WHEN State = 'AL' THEN 1 ELSE 0 END as STATE_AL,
CASE WHEN State = 'AK' THEN 1 ELSE 0 END as STATE_AK,
CASE WHEN State = 'AZ' THEN 1 ELSE 0 END as STATE_AZ,
CASE WHEN State = 'AR' THEN 1 ELSE 0 END as STATE_AR,
CASE WHEN State = 'AS' THEN 1 ELSE 0 END as STATE_AS,
CASE WHEN State = 'CA' THEN 1 ELSE 0 END as STATE_CA,
CASE WHEN State = 'CO' THEN 1 ELSE 0 END as STATE_CO,
CASE WHEN State = 'CT' THEN 1 ELSE 0 END as STATE_CT,
CASE WHEN State = 'DC' THEN 1 ELSE 0 END as STATE_DC,
CASE WHEN State = 'FL' THEN 1 ELSE 0 END as STATE_FL,
CASE WHEN State = 'GA' THEN 1 ELSE 0 END as STATE_GA,
CASE WHEN State = 'HI' THEN 1 ELSE 0 END as STATE_HI,
CASE WHEN State = 'ID' THEN 1 ELSE 0 END as STATE_ID,
CASE WHEN State = 'IL' THEN 1 ELSE 0 END as STATE_IL,
CASE WHEN State = 'IN' THEN 1 ELSE 0 END as STATE_IN,
CASE WHEN State = 'IA' THEN 1 ELSE 0 END as STATE_IA,
CASE WHEN State = 'KS' THEN 1 ELSE 0 END as STATE_KS,
CASE WHEN State = 'KY' THEN 1 ELSE 0 END as STATE_KY,
CASE WHEN State = 'LA' THEN 1 ELSE 0 END as STATE_LA,
CASE WHEN State = 'ME' THEN 1 ELSE 0 END as STATE_ME,
CASE WHEN State = 'MD' THEN 1 ELSE 0 END as STATE_MD,
CASE WHEN State = 'MA' THEN 1 ELSE 0 END as STATE_MA,
CASE WHEN State = 'MI' THEN 1 ELSE 0 END as STATE_MI,
CASE WHEN State = 'MN' THEN 1 ELSE 0 END as STATE_MN,
CASE WHEN State = 'MS' THEN 1 ELSE 0 END as STATE_MS,
CASE WHEN State = 'MO' THEN 1 ELSE 0 END as STATE_MO,
CASE WHEN State = 'MT' THEN 1 ELSE 0 END as STATE_MT,
CASE WHEN State = 'NE' THEN 1 ELSE 0 END as STATE_NE,
CASE WHEN State = 'NV' THEN 1 ELSE 0 END as STATE_NV,
CASE WHEN State = 'NH' THEN 1 ELSE 0 END as STATE_NH,
CASE WHEN State = 'NJ' THEN 1 ELSE 0 END as STATE_NJ,
CASE WHEN State = 'NM' THEN 1 ELSE 0 END as STATE_NM,
CASE WHEN State = 'NY' THEN 1 ELSE 0 END as STATE_NY,
CASE WHEN State = 'NC' THEN 1 ELSE 0 END as STATE_NC,
CASE WHEN State = 'ND' THEN 1 ELSE 0 END as STATE_ND,
CASE WHEN State = 'OH' THEN 1 ELSE 0 END as STATE_OH,
CASE WHEN State = 'OK' THEN 1 ELSE 0 END as STATE_OK,
CASE WHEN State = 'OR' THEN 1 ELSE 0 END as STATE_OR,
CASE WHEN State = 'PA' THEN 1 ELSE 0 END as STATE_PA,
CASE WHEN State = 'RI' THEN 1 ELSE 0 END as STATE_RI,
CASE WHEN State = 'SC' THEN 1 ELSE 0 END as STATE_SC,
CASE WHEN State = 'SD' THEN 1 ELSE 0 END as STATE_SD,
CASE WHEN State = 'TN' THEN 1 ELSE 0 END as STATE_TN,
CASE WHEN State = 'TX' THEN 1 ELSE 0 END as STATE_TX,
CASE WHEN State = 'UT' THEN 1 ELSE 0 END as STATE_UT,
CASE WHEN State = 'VT' THEN 1 ELSE 0 END as STATE_VT,
CASE WHEN State = 'VA' THEN 1 ELSE 0 END as STATE_VA,
CASE WHEN State = 'WA' THEN 1 ELSE 0 END as STATE_WA,
CASE WHEN State = 'WV' THEN 1 ELSE 0 END as STATE_WV,
CASE WHEN State = 'WI' THEN 1 ELSE 0 END as STATE_WI,
CASE WHEN State = 'WY' THEN 1 ELSE 0 END as STATE_WY
FROM BABYTABLE;결과:
장바구니 분석
연결 규칙에 대한 장바구니 분석 또는 마이닝을 수행할 때 첫 번째 단계는 종종 각 거래를 단일 레코드로 집계하도록 데이터 형식을 지정하는 것입니다. 랩톱에서는 어려울 수 있지만 데이터 웨어하우스는 이 데이터를 효율적으로 처리하도록 설계되었습니다.
WITH order_detail as (
SELECT
SALESORDERNUMBER,
listagg(ENGLISHPRODUCTNAME, ', ') WITHIN group (
order by
ENGLISHPRODUCTNAME
) as ENGLISHPRODUCTNAME_listagg,
COUNT(ENGLISHPRODUCTNAME) as num_products
FROM
transactions
GROUP BY
SALESORDERNUMBER
)
SELECT
ENGLISHPRODUCTNAME_listagg,
count(SALESORDERNUMBER) as NumTransactions
FROM
order_detail
where
num_products > 1
GROUP BY
ENGLISHPRODUCTNAME_listagg
order by
count(SALESORDERNUMBER) desc;결과:
시계열 집계
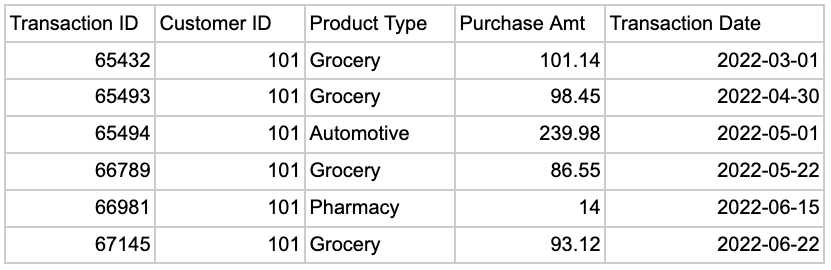
시계열 집계는 데이터 과학자뿐만 아니라 분석에도 사용됩니다. 그들을 어렵게 만드는 것은 윈도우 함수가 데이터의 형식을 올바르게 지정해야 한다는 것입니다.
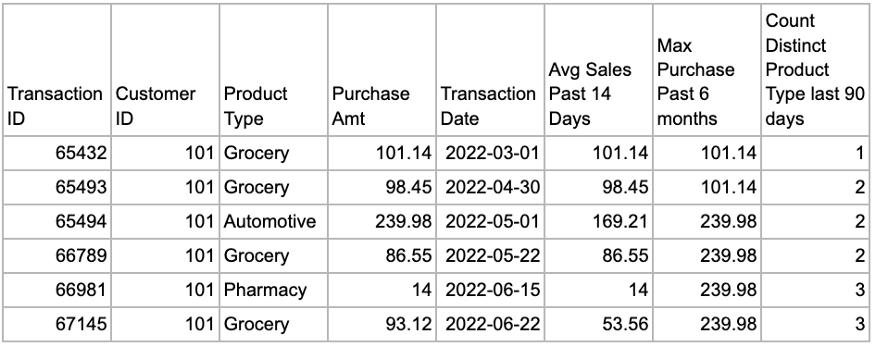
예를 들어 지난 14일 동안의 평균 판매 금액을 계산하려는 경우 창 함수를 사용하려면 모든 판매 데이터를 하루에 한 행으로 분할해야 합니다. 불행히도 이전에 판매 데이터로 작업한 적이 있는 사람은 일반적으로 거래 수준에서 저장된다는 것을 알고 있습니다. 여기에서 시계열 집계가 유용합니다. 전체 데이터 세트를 다시 포맷하지 않고도 집계된 기록 지표를 생성할 수 있습니다. 한 번에 여러 메트릭을 추가하려는 경우에도 유용합니다.
- 지난 14일 동안의 평균 판매
- 지난 6개월 동안 가장 큰 구매
- 지난 90일 동안 고유한 제품 유형 계산
창 기능을 사용하려면 각 메트릭을 여러 단계로 독립적으로 작성해야 합니다.
이를 처리하는 더 좋은 방법은 CTE(공통 테이블 표현식)를 사용하여 사전 집계된 각 기록 창을 정의하는 것입니다.
예를 들어:
WITH BASIC_OFFSET_14DAY AS (
SELECT
A.CustomerID,
A.TransactionDate,
AVG(B.PurchaseAmount) as AVG_PURCHASEAMOUNT_PAST14DAY,
MAX(B.PurchaseAmount) as MAX_PURCHASEAMOUNT_PAST14DAY,
COUNT(DISTINCT B.TransactionID) as COUNT_DISTINCT_TRANSACTIONID_PAST14DAY
FROM
My_First_Table A
INNER JOIN My_First_Table B ON A.CustomerID = B.CustomerID
AND 1 = 1
WHERE
B.TransactionDate >= DATEADD(day, -14, A.TransactionDate)
AND B.TransactionDate <= A.TransactionDate
GROUP BY
A.CustomerID,
A.TransactionDate
),
BASIC_OFFSET_90DAY AS (
SELECT
A.CustomerID,
A.TransactionDate,
AVG(B.PurchaseAmount) as AVG_PURCHASEAMOUNT_PAST90DAY,
MAX(B.PurchaseAmount) as MAX_PURCHASEAMOUNT_PAST90DAY,
COUNT(DISTINCT B.TransactionID) as COUNT_DISTINCT_TRANSACTIONID_PAST90DAY
FROM
My_First_Table A
INNER JOIN My_First_Table B ON A.CustomerID = B.CustomerID
AND 1 = 1
WHERE
B.TransactionDate >= DATEADD(day, -90, A.TransactionDate)
AND B.TransactionDate <= A.TransactionDate
GROUP BY
A.CustomerID,
A.TransactionDate
),
BASIC_OFFSET_180DAY AS (
SELECT
A.CustomerID,
A.TransactionDate,
AVG(B.PurchaseAmount) as AVG_PURCHASEAMOUNT_PAST180DAY,
MAX(B.PurchaseAmount) as MAX_PURCHASEAMOUNT_PAST180DAY,
COUNT(DISTINCT B.TransactionID) as COUNT_DISTINCT_TRANSACTIONID_PAST180DAY
FROM
My_First_Table A
INNER JOIN My_First_Table B ON A.CustomerID = B.CustomerID
AND 1 = 1
WHERE
B.TransactionDate >= DATEADD(day, -180, A.TransactionDate)
AND B.TransactionDate <= A.TransactionDate
GROUP BY
A.CustomerID,
A.TransactionDate
)
SELECT
src.*,
BASIC_OFFSET_14DAY.AVG_PURCHASEAMOUNT_PAST14DAY,
BASIC_OFFSET_14DAY.MAX_PURCHASEAMOUNT_PAST14DAY,
BASIC_OFFSET_14DAY.COUNT_DISTINCT_TRANSACTIONID_PAST14DAY,
BASIC_OFFSET_90DAY.AVG_PURCHASEAMOUNT_PAST90DAY,
BASIC_OFFSET_90DAY.MAX_PURCHASEAMOUNT_PAST90DAY,
BASIC_OFFSET_90DAY.COUNT_DISTINCT_TRANSACTIONID_PAST90DAY,
BASIC_OFFSET_180DAY.AVG_PURCHASEAMOUNT_PAST180DAY,
BASIC_OFFSET_180DAY.MAX_PURCHASEAMOUNT_PAST180DAY,
BASIC_OFFSET_180DAY.COUNT_DISTINCT_TRANSACTIONID_PAST180DAY
FROM
My_First_Table src
LEFT OUTER JOIN BASIC_OFFSET_14DAY ON BASIC_OFFSET_14DAY.TransactionDate = src.TransactionDate
AND BASIC_OFFSET_14DAY.CustomerID = src.CustomerID
LEFT OUTER JOIN BASIC_OFFSET_90DAY ON BASIC_OFFSET_90DAY.TransactionDate = src.TransactionDate
AND BASIC_OFFSET_90DAY.CustomerID = src.CustomerID
LEFT OUTER JOIN BASIC_OFFSET_180DAY ON BASIC_OFFSET_180DAY.TransactionDate = src.TransactionDate
AND BASIC_OFFSET_180DAY.CustomerID = src.CustomerID;결과:
결론
이 글이 데이터 실무자가 최신 데이터 스택 내에서 작업할 때 직면하게 될 다양한 문제에 대한 정보를 제공하는 데 도움이 되기를 바랍니다. SQL은 클라우드 웨어하우스 쿼리와 관련하여 양날의 검입니다. 클라우드 데이터 웨어하우스에서 컴퓨팅을 중앙 집중화하면 속도가 증가하지만 때로는 약간의 추가 SQL 기술이 필요합니다. 이 글이 질문에 답하고 이러한 문제를 해결하는 데 필요한 구문과 배경을 제공하는 데 도움이 되었기를 바랍니다.
'Daily Review' 카테고리의 다른 글
| 시계열 분석 및 예측에 대한 종합 가이드 (1) (0) | 2022.09.11 |
|---|---|
| 올바른 데이터에 대한 올바른 차트 (0) | 2022.09.11 |
| 데이터 분석: 데이터에서 정보와 지식을 추출하는 프로세스 (0) | 2022.09.10 |
| 5개의 데이터 시각화 대시보드 템플릿 (1) | 2022.09.10 |
| 데이터 과학자가 되어서는 안 되는 이유 (2) | 2022.09.10 |




댓글