데이터 전처리
데이터 준비는 일반적으로 다음 단계로 구성됩니다.
- 데이터 수집(데이터 세트 생성)
- 데이터 탐색(데이터 이해)
- 데이터 서식 지정(정리, 크기 조정, 품질 개선)
- 기능 엔지니어링 및 데이터 변환(예: 주소 문자열을 필요한 정보로 선택하고 이를 국가, 도시, 거리에 대한 정보 조각으로 나누기)
그러나 이미 데이터가 있을 때 정확히 무엇을 합니까? 글쎄, 그것은 우리가 작업하는 데이터와 작업에 따라 약간 다릅니다.
1) 이미지의 경우:
- 각 이미지가 예상되는 것을 나타내는지 확인
- 다른 이미지 청소
- 이미지 크기 조정/크기 조정
2) 테이블 및 숫자 데이터의 경우:
- 데이터 탐색
- 평균 결측값 및 이상값 제거 또는 채우기
- 추가 열 삭제
- 필드를 검토하여 정보를 제공하고 작업하기에 좋은지 확인
- 변수를 선택하고 그들 사이의 관계를 정의
3) 텍스트의 경우:
- 언어 식별
- 문장을 토큰화(문장을 단어로 나누기)
- drop stop words — 일반적으로 필요하지만 작업에 따라 다름
- (선택 사항) lemmatize/stem 토큰, 작업에 따라 다름
데이터 보강
데이터 전처리는 데이터 세트에 있는 모든 데이터와 관련이 있지만 데이터 증대는 훈련 세트에만 적용됩니다. 변환된 데이터로 데이터 세트 크기를 늘리는 데 사용됩니다.
자르기, 확대/축소, 미러링, 조명 변경 등과 같은 다양한 변환을 사용하여 확대가 수행되는 이미지 데이터에 대한 예를 만드는 것이 더 쉽습니다.
반면에 NLP에서는 특히 한 단어가 아닌 논리적 문장이나 텍스트로 작업하는 경우 약간 더 어렵습니다. 여러 가지 방법이 있으며 그 중 하나는 역 번역입니다. 데이터를 다른 언어로 번역하고 역으로 번역하면 됩니다. 아이디어는 유지하지만 표현은 변경됩니다.
표 형식의 데이터에서는 이웃 값을 사용하여 약간 다른 데이터 포인트를 생성하고 SMOTE (조금 더 낮게 설명) 와 같은 불균형 데이터 처리와 유사한 기술을 생성할 수 있습니다 .
불균형 데이터
불균형 데이터는 한 클래스의 모드 데이터가 다른 클래스보다 있을 때, 한두 개 또는 10개의 이미지/텍스트가 아니라 훨씬 더 많습니다.
그게 뭐가 문제야? 글쎄, 그러한 데이터에 대해 학습된 모델은 잘못된 예측을 할 것입니다: 클래스가 더 자주 충족될 가능성이 더 높다고 생각하고 다른 예측 중에서 가양성을 수행하며, 각각 자신이 만난 클래스에 대해 덜 정확한 예측을 하는 경향이 있을 것입니다. 덜, 거짓 음성을 예측합니다.
이 문제를 해결하기 위해 데이터에 따라 함께 사용하거나 별도로 시도할 수 있는 몇 가지 접근 방식이 있습니다.
1. 계층화
훈련/테스트 분할에서 클래스 간의 원래 비율 또는 균형을 유지합니다. scikit-learn의 train_test_split 에는 이에 대한 stratify 인수가 있습니다. 모든 종류의 데이터 및 작업과 함께 사용할 수 있습니다.
모델링에 도움이 될 것이지만 우리가 무엇을 더 할 수 있는지 봅시다.
2. 오버샘플링과 언더샘플링
언더샘플링은 빈도가 높은 클래스를 삭제하여 비율을 높이는 것입니다.
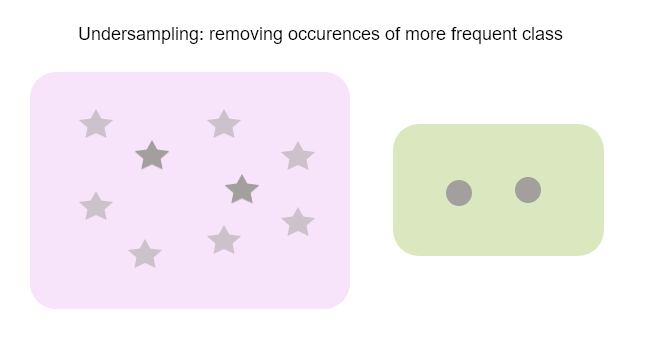
하지만 데이터의 양이 많을 때 좋습니다. 그렇지 않으면 어떻게 합니까? 대신 덜 빈번한 클래스의 발생을 복제 하는 오버샘플링 을 사용하십시오.
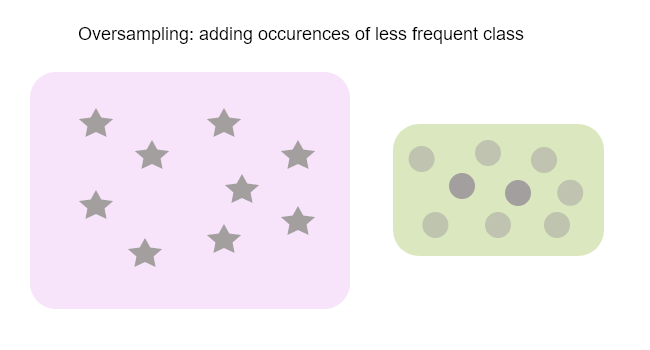
여러 가지 방법이 있는데 그 중 테이블 데이터로 사용되는 SMOTE에 대해 확실히 알아야 합니다.
SMOTE(Synthetic Minority Oversampling Technique)는 원본 데이터 항목을 약간 변경하여 새 데이터 항목을 생성합니다. 데이터 세트의 중복은 좋지 않기 때문입니다. 따라서 소수 클래스와 매우 유사하지만 정확한 사본이 아닌 데이터를 생성합니다.
3. F1 점수와 같은 올바른 측정항목 사용
단순 정확도는 불균형 데이터와 잘 작동하지 않습니다. 그러나 F1 점수는 여기에서 도움이 될 수 있습니다. 정확도와 재현율의 조화 평균입니다. 공식은 다음과 같습니다. F1 = 2(P*R)/P + R, 여기서 P는 정밀도, R은 재현율
작업이 분류인 경우 모든 데이터와 함께 사용할 수 있습니다.
정밀도 및 재현율
때로는 보여주는 것이 더 좋습니다. 그래서 여기에 우리 모델의 예측이 있습니다:
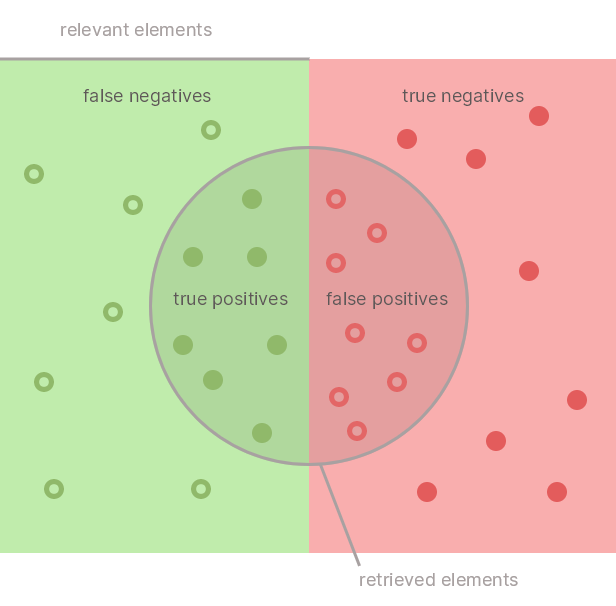
여기서 정밀도 는 예측된 참 양성 대 참 양성 및 거짓 양성(모든 예측 양성)의 비율입니다.
반면 재현율 은 참 긍정과 거짓 부정(데이터 세트의 모든 긍정)에 대한 참 긍정의 비율입니다.
활성화 기능
활성화 함수는 가중치 합을 계산하고 거기에 편향을 더하여 뉴런을 활성화할지 여부를 결정합니다. 그것이 없으면 신경망은 그 의미에서 선형 회귀 모델일 뿐이며 활성화 함수는 출력에 비선형성을 도입합니다.
각 작업에는 최적의 활성화 기능이 있으며 다음은 잘 알려진 몇 가지 기능입니다.
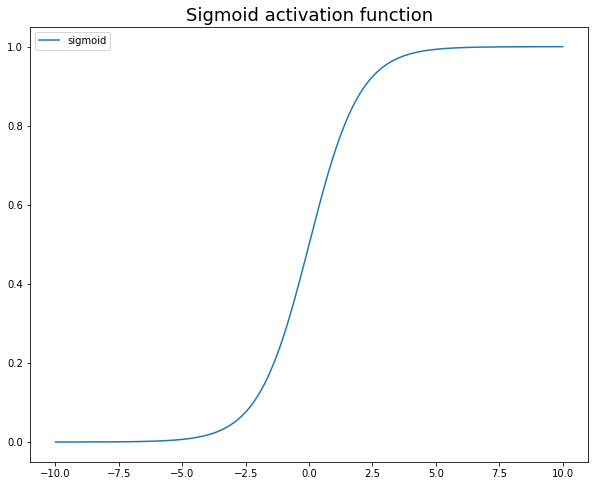
1. 시그모이드/로지스틱 함수
알고리즘에 대한 이전 기사를 읽으면 이진 분류에 사용된다는 것을 기억할 수 있으며 출력이 [0:1] 범위에 있어야 하는 경우에도 사용할 수 있습니다. 문제는 학습을 느리게 만드는 그라디언트를 포화시키고 죽인다는 것입니다.
공식은 f(x) = 1/(1 + ex)
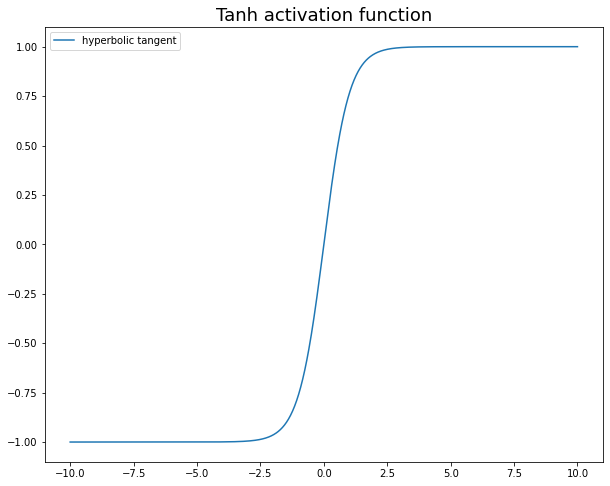
2. Tanh
시그모이드의 이동된 버전이며 기울기도 포화되지만 값은 [-1:1] 범위에 있습니다. 데이터를 중앙에 배치하고 평균을 0으로 만드는 데 도움이 되므로 신경망의 은닉 계층에서 일반적으로 사용되며 다음 계층에서 더 쉽게 학습할 수 있습니다.
공식은 f(x) = 2/(1 + e-2x) -1 또는 f(x) = 2 * 시그모이드(2x) -1입니다.
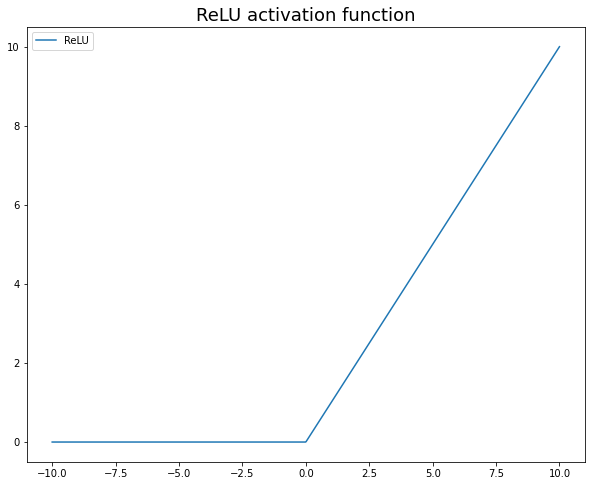
3. ReLU
이전 두 개보다 훨씬 빠르게 학습하는 모델로 가장 널리 사용되는 활성화 함수입니다. 이전 두 가지만큼 계산 비용이 많이 들지 않으며 소멸 기울기에 민감하지 않습니다. 0보다 작거나 같은 모든 값에 대해 0을 반환하고 0보다 크거나 같은 모든 값에 대해 값을 반환합니다. 또한 무엇을 사용해야 할지 잘 모를 때 ReLU를 사용하라는 조언도 보았습니다. :)
공식은 f(x) = max(0,x)입니다.
정규화
정규화는 네트워크가 과적합될 수 있는 너무 복잡한 모델을 학습하는 것을 방지하는 기술입니다.
드롭아웃은 네트워크 계층 출력에서 임의의 뉴런을 삭제하여 정규화하는 간단한 방법입니다.
드롭아웃은 다른 계층 간의 신경망 모델 아키텍처에서 정의되어야 합니다. 이 방법은 뉴런의 어느 부분을 무시할지 정의하는 매개변수를 도입합니다([0.:1] 범위). 이웃 뉴런이 다른 노드에 대한 책임을 지도록 만드는 것은 매우 잘 작동하며 제한된 데이터 세트 크기 측면에서 과적합을 방지하는 데 도움이 됩니다.
L1(올가미 정규화) 및 L2(릿지 정규화) 정규화를 통해 비용 함수에 페널티를 추가하여 가중치를 0으로 푸시합니다.
scikit의 L1 학습: sklearn.linear_model.Lasso
scikit의 L2 학습: sklearn.linear_model.Ridge
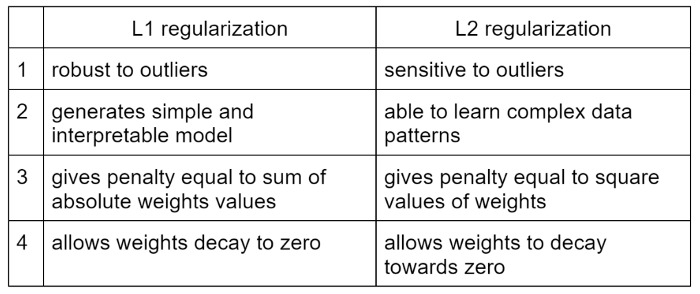
컴퓨터 비전 문제의 경우 L2가 종종 더 나은 선택이라고 하지만 L1은 일반적으로 이상값에 대한 무관심을 위해 선택되며 기능 선택에 유용합니다. L2 접근 방식은 SVM 알고리즘에서도 구현됩니다.
또한 모든 이점이 있는 L1 및 L2 방법의 조합인 Elastic Net 정규화도 있습니다.
scikit 학습의 Elastic Net: linear_model.ElasticNet
손실 및 비용 함수
비용 함수가 무엇인지 정리하고 싶었습니다.
비용 함수는 모든 훈련 샘플에 대한 손실인 반면 손실 함수는 하나의 입력에만 해당합니다.
'Daily Review' 카테고리의 다른 글
| Matplotlib 차트를 향상시키는 7가지 간단한 방법 (0) | 2022.09.12 |
|---|---|
| 시계열 분석 및 예측에 대한 종합 가이드 (3) (0) | 2022.09.12 |
| 시계열 분석 및 예측에 대한 종합 가이드 (2) (0) | 2022.09.12 |
| 시계열 분석 및 예측에 대한 종합 가이드 (1) (0) | 2022.09.11 |
| 올바른 데이터에 대한 올바른 차트 (0) | 2022.09.11 |




댓글