
소개
불균형 데이터 세트로 작업하는 것은 일부 고전적인 머신 러닝 접근 방식에서 문제가 될 수 있지만 클래스 간에 데이터의 자연스러운 분포가 동일하지 않은 일부 상황이 있습니다. 이것은 Fraud Detection 문제의 전형입니다.
Kaggle 의 다음 데이터 세트를 사용 하여 합법적인 거래가 많이 있고 전체 데이터의 0.17% 만이 사기 임을 알 수 있습니다.. 데이터 분포의 불균형이 있는 분류 문제에서 연구는 일반적으로 희귀 데이터 식별에 중점을 둡니다. 머신 러닝 모델의 성능은 주로 소수 계층의 예측에서 얻은 결과를 기반으로 측정되어야 합니다.
모델을 검증하기 위한 올바른 메트릭을 선택하는 방법과 우리 상황에서 Precision-Recall 트레이드오프의 실질적인 의미를 보여줍니다. 마지막으로 편향된 클래스 분포를 처리하는 방법과 다양한 기계 학습 알고리즘으로 얻은 결과를 확인하는 방법을 강조합니다.
모델 설명 가능성이 중요한 이유
사기 적발에서는 최종 예측뿐만 아니라 시스템을 그 결론으로 이끕니다. 은행은 자동 사기 분류 시스템을 사용하여 의심스러운 상황을 감지할 수 있습니다. 경보가 울리면 은행 직원이 시스템에서 가상 사기를 식별한 이유를 분석하고 전문가가 최종 결정을 내릴 것입니다. 모델이 그 이유를 설명할 수 없으면 당국이나 법적 목적으로 사용할 수 없습니다.
물론 항상 그렇게 중요한 것은 아니지만 분류의 이유를 설명할 수 있는 모델을 갖는 것은 매우 중요할 수 있습니다.
어떤 접근 방식을 사용합니까?
다양한 접근 방식으로 사기를 감지할 수 있습니다. 다양한 연구에서 신경/심층 네트워크 또는 고전적인 기계 학습 알고리즘 을 기반으로 하는 솔루션을 보여줍니다 . 우리는 후자의 메커니즘을 사용할 것입니다. 음.. 알았어, 왜?
신경망과 같은 도구는 일반적으로 블랙박스 모델입니다. 따라서 신경망에 의해 거래가 특정 방식으로 분류된 규칙이나 이유를 파악하는 것은 매우 어려울 수 있지만 이 정보는 앞에서 언급한 것처럼 사기 탐지에서 매우 중요할 수 있습니다. Decision Tree 와 같은 훈련된 트리 기반 모델 은 각 분류 레이블( Fraud 또는 Non-Fraud )에 대해 시스템에서 추론한 규칙에 대한 아이디어를 제공할 수 있습니다.).
매우 쉽습니다. 분류 기준을 이해하려면 분류 트리의 루트에서 리프까지의 경로만 따라가면 됩니다. 마지막으로 신경망은 매우 강력한 방법론이지만 때로는 이러한 도구를 사용할 필요가 없는 경우도 있습니다. 우리는 다음 방법론을 훈련하고 테스트할 것입니다.
- 결정 트리
- 랜덤 포레스트
- Xgboost
- 로지스틱 회귀
- Svm
- K-nn
치우친 데이터 분포
분류기는 왜도에 대해 강건하거나 그렇지 않을 수 있습니다. 소수 클래스는 불균형 데이터 세트의 통계 모델에 대한 이상값으로 작용할 수 있으며 이상값은 모델의 성능에 부정적인 영향을 미칩니다.
일부 모델은 이상값을 처리할 만큼 충분히 강력하지만 일반적으로 문제는 모델이 사용되는 제한적입니다. 불균형 데이터 세트로 작업할 때의 문제는 일반적으로 머신 러닝 기술이 데이터 세트를 무시할 것이고, 결론적으로는 일반적으로 가장 중요한 결과여야 하지만 소수 계층에서 성능이 저하된다는 것입니다.
이 문제와 관련하여 가장 좋은 방법은 데이터의 균형을 유지하고 왜도 제거 프로세스를 수행하는 것입니다. 불균형 데이터 세트에 대한 머신 러닝 모델 교육은 우리 모델에 영향을 줄 수 있습니다.
데이터 분배 균형 조정
이 문제는 데이터세트를 서로 다른 클래스의 동일한 수의 요소가 있는 새 데이터세트로 변환하여 해결할 수 있습니다. 2 가지 가능한 솔루션이 있습니다.
- 다수 클래스를 언더샘플링합니다 .
- 합성 샘플을 생성하여 소수 클래스를 오버샘플링 합니다.
세 번째 하이브리드 방식 은 오버 샘플링과 언더 샘플링의 두 가지 방법을 모두 적용 할 수 있습니다 .
이러한 전략이 작동하는 이유는 무엇입니까? 언더샘플링 전략을 사용 하면 다수 클래스의 일부 레코드가 중복 된다고 가정 하지만 이 방법론의 한계는 데이터를 제거하여 관련 정보를 제거할 수 있다는 것입니다. 오버샘플링 전략을 사용하여 클래스 간의 데이터 분포가 동일할 때까지 소수 클래스의 합성 예제가 생성 됩니다 . 이것은 클래스 분포의 균형을 맞출 수 있지만 모델에 추가 정보를 제공하지 않습니다. 위험은 소수 계층에 과적합됩니다.
밸런싱 알고리즘
Random under/over-sample : 가장 쉬운(그리고 덜 효과적인) 방법은 다수 클래스의 임의 레코드를 제거하고 소수 클래스의 임의 예제를 복제하는 것입니다.
SMOTE: 기능 공간에서 가까운 예제를 선택하여 작동하며 소수 클래스에서 임의의 예제가 먼저 선택됩니다. 그런 다음 해당 예제에서 k 의 최근접 이웃을 찾습니다(일반적으로 k=5 ). 합성 예제는 선택된 예제와 k개의 이웃 사이의 선에서 무작위로 선택된 지점에서 생성됩니다 . 소수 클래스의 새로운 합성 예제가 소수 클래스의 기존 예제와 피쳐 공간에서 비교적 가깝게 생성되기 때문에 접근 방식이 효과적입니다.
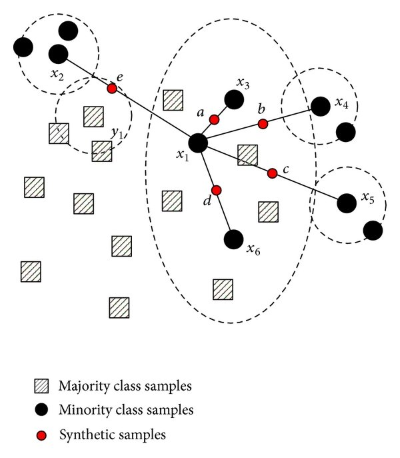
ADASYN: SMOTE 와 매우 유사합니다 . 이러한 샘플을 만든 후 점에 임의의 작은 값을 추가하여 보다 사실적으로 만듭니다. 모든 샘플이 상위에 선형적으로 상관되는 대신에 약간 더 많은 분산이 있습니다.
SMOTE TOMEK : 소수 클래스의 오버샘플링을 위해 SMOTE 를 적용합니다. 이상치를 줄이고 정의된 패턴을 얻기 위해 Tomek Link는 소수 클래스와 다수 클래스 모두에 적용됩니다. Tomek 링크는 데이터 정리 및 이상값 제거 프로세스입니다. 각각이 동일한 클래스의 하나의 예제가 아닌 다른 클래스의 예제에 더 가까운 경우 서로 다른 클래스의 2개의 레코드를 제거합니다.
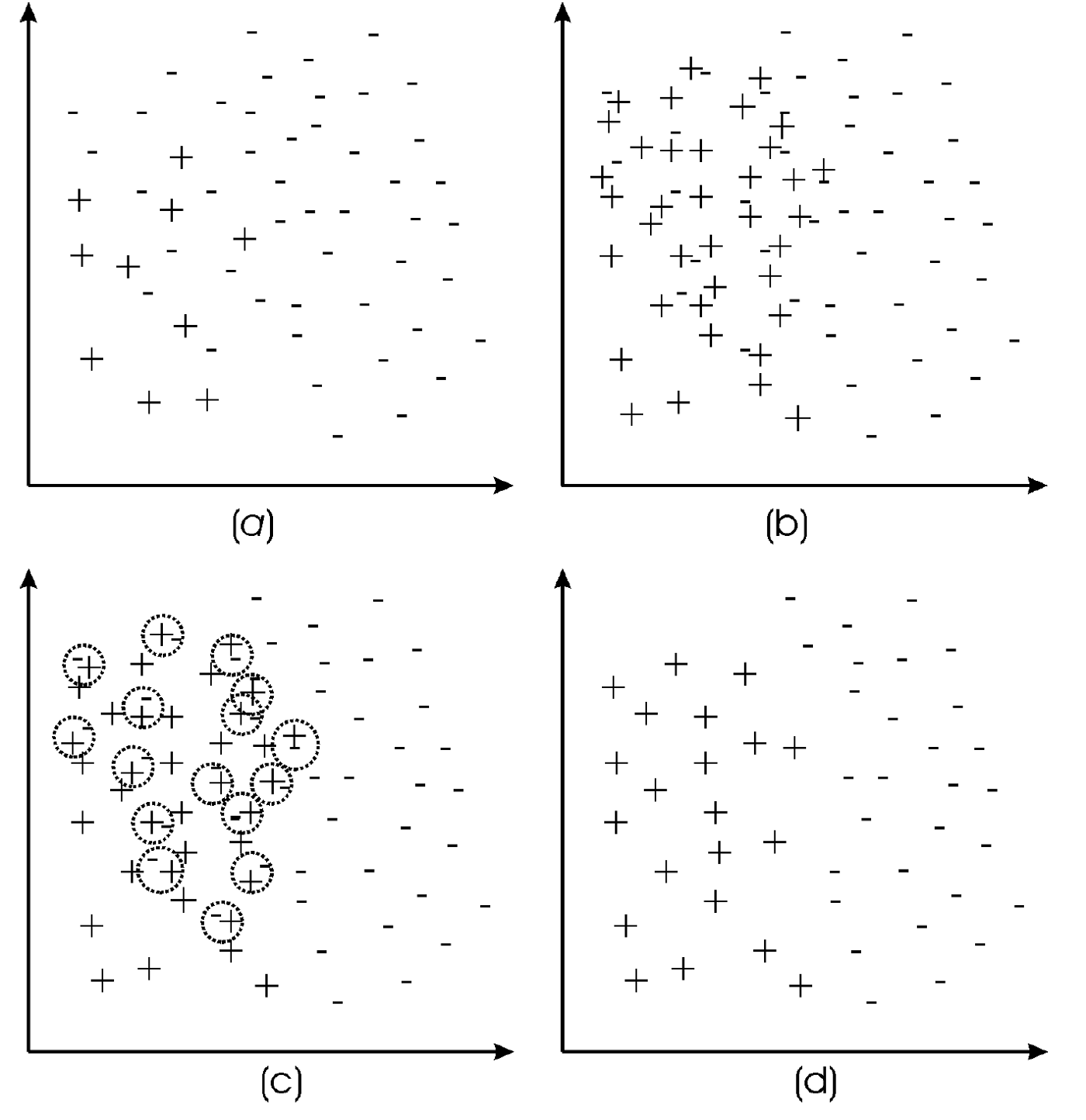
SMOTE ENN : SMOTE TOMEK 과 마찬가지로 세척 및 이상치 탐지 프로세스가 더 효과적입니다. 예를 들어, 하나의 레코드를 제거해야 하는지 여부를 결정하는 k-최근접 이웃 프로세스를 기반으로 합니다. 청소 프로세스가 너무 공격적이면 중요한 정보를 잃을 수 있습니다.
'Daily Review' 카테고리의 다른 글
| 60일 내의 데이터 분석이란. (0) | 2022.09.07 |
|---|---|
| 라벨 불균형 사기 탐지(Fraud Detection)의 분류 모델링 - 2 (1) | 2022.09.06 |
| 나를 Kaggle 마스터로 만든 10가지 노트북 (0) | 2022.09.06 |
| 비지도 학습 기법을 적용한 사기 탐지 (Fraud Detection) (0) | 2022.09.05 |
| 데이터 분석 분야를 바꿀 3가지 Python 패키지 (0) | 2022.09.05 |



댓글