일괄 처리를 위한 Facebook의 Prophet을 사용한 시계열 이상값 감지

2016년에 출시된 Getcontact는 월간 활성 사용자가 5천만 명 이상이고 4개 대륙에 걸쳐 입지가 확대되고 있는 전 세계 최고의 모바일 ID 및 사기 방지 서비스 중 하나로 통합되었습니다 .
Getcontact 애플리케이션의 이러한 급속한 성장은 등록된 사용자 및 확인된 사용자와 같은 많은 기본 KPI를 기술 측면에서 제어할 수 있음을 의미합니다. KPI를 매일 검토하고 머신 러닝 알고리즘으로 지원하면 성장 전략을 보다 정확하게 계획하는 데 도움이 됩니다. 사용자 행동의 변화를 면밀히 모니터링하면 일부 중요한 경우 시스템 과부하를 예방하고 균형을 유지하는 데 도움이 됩니다. 그런 다음 KPI 수에서 올바른 이상 지점을 감지하면 부하를 현명하게 분배할 수 있습니다.
목표
사용자 수와 나날이 증가하는 트래픽에 따라 중요한 KPI를 관리합니다.
이상 감지
이상치 감지라고도 하는 이상 감지는 지정된 데이터 세트에서 갑작스러운 급증 또는 감소를 유발하는 비정상적인 관찰을 찾는 데 사용되는 식별 기술입니다 . 이 기술에는 이상 문제를 올바르게 해결하기 위해 많은 솔루션 이 있지만 먼저 원시 데이터 구조를 자세히 조사해야 합니다. 원시 데이터 구조를 조사한 후 문제를 정의하기 위해 데이터 과학 인터뷰 의 필수 질문을 할 수 있습니다. 우리의 문제는 지도 학습입니까 아니면 비지도 학습입니까?

오늘날, 비정상 문제는 레이블이 없는 데이터에 더 많은 응용 프로그램을 필요로 합니다. Getcontact의 이상 탐지 프로젝트를 시작하면서 프로젝트를 종단 간 설계하기 위해 샘플 데이터를 추출했습니다. 테스트 데이터베이스에서 얻은 원시 데이터를 분석할 때 세부 사항으로 문제를 설명했습니다. 샘플 데이터에서 얻은 통찰력을 사용하여 모델 데이터를 준비하기 위해 파이썬 코드를 작성했습니다. 모델 원시 데이터는 국가 분석에서 Getcontact의 생산 데이터베이스에서 레이블이 지정되지 않은 KPI 데이터를 집계하여 짧은 시간에 생성되었습니다. 이 기사에서는 시계열 기반 원시 데이터에서 이론적으로 이상을 감지하는 방법에 대해 설명합니다. 레이블이 지정되지 않은 시계열 데이터에서 Facebook의 Prophet 을 사용하여 간단한 이상값 감지를 수행하겠습니다 . 이 기사에 사용되는 레이블이 없는 일일 데이터는 무작위로 생성되었습니다.
문제 정의
국가 분석에서 KPI 값의 급격한 증가 및 감소를 어떻게 이해하고 추적할 수 있습니까?

Python 이상값 감지 도구 상자(PyOD)
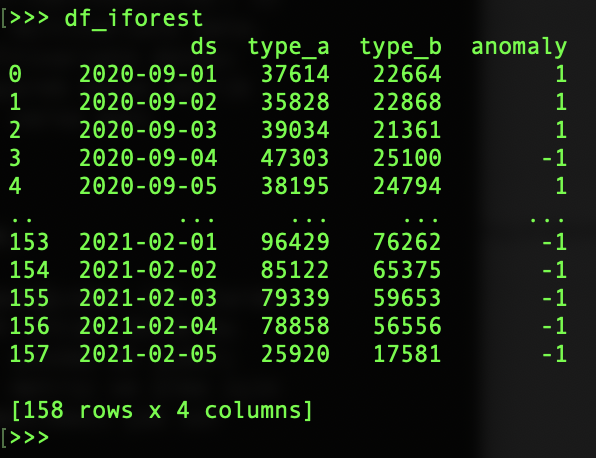
Facebook Prophet에 앞서 PyOD 패키지에 대해 이야기하고 싶습니다. PyOD 는 다변수 데이터에서 외부 개체를 감지하기 위한 포괄적이고 확장 가능한 Python 도구 키트입니다. PyOD에는 30개 이상의 탐지 알고리즘이 포함되어 있습니다. 이러한 알고리즘 중 다변수 데이터를 모델링할 수 있는 Isolation Forest 알고리즘을 시도했습니다. PyOD IForest는 더 많은 기능을 갖춘 scikit-learn Isolation Forest의 래퍼입니다. 격리 포리스트 알고리즘은 scikit-learn 패키지에서 직접 사용할 수도 있습니다. 국가를 선택하고 나머지 KPI 데이터에서 피벗 데이터를 만들었습니다. 따라서 아래 이미지에서 볼 수 있듯이 선택한 국가의 모든 시간 기반 KPI 데이터에 단일 이상 레이블이 할당 됩니다.
첫째, KPI 메트릭을 독립적으로 평가하면 이상 지점을 더 잘 포착할 수 있기 때문에 각 메트릭에 대해 별도의 격리 알고리즘을 실행하여 이상을 감지했습니다. 그러나 데이터가 불충분한 일부 국가의 모델 결과는 충분하지 않았습니다. 모델 방법의 매개변수를 미세 조정하여 이 문제를 해결할 수 있습니다. 특히 오염이라는 매개변수는 종류와 국가별로 다른 값을 설정해야 합니다. 이 방법을 선택하여 프로젝트를 설계하면 프로젝트를 유지 관리하기가 쉽지 않아 FBProphet 패키지를 사용하기로 결정했습니다.
해결책
훌륭한 시계열 분석 패키지인 Facebook Prophet.
FB Prophet
FB Prophet은 Facebook에서 출시한 오픈 소스 소프트웨어입니다. 그것의 설치와 사용법은 꽤 쉽습니다. 주로 시계열 예측에 사용됩니다. 게다가, 내부의 모든 미세 조정 부분을 수행할 수 있는 이 강력한 라이브러리는 우리의 삶에서 이상값을 찾기 쉽게 만듭니다. FB Prophet 은 이상값, 누락된 데이터 및 시계열의 급격한 변화에 강합니다. 생성하는 예측과 함께 불확실성 구간(yhat_upper, yhat_lower)을 제공합니다. 불확도 구간을 벗어난 지점은 이상 지점으로 표시됩니다. 이런 식으로 몇 가지 코드를 실행하여 전날이 이상값인지 여부를 알 수 있습니다.
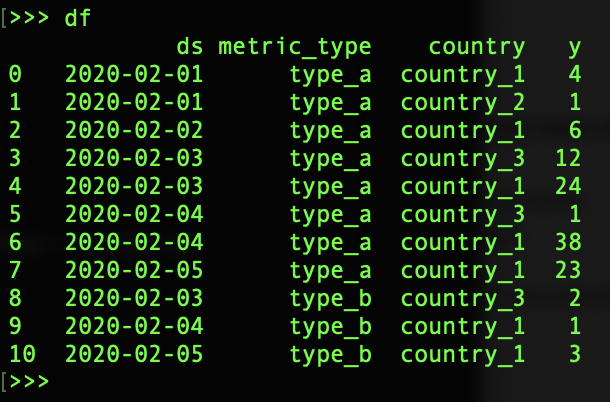
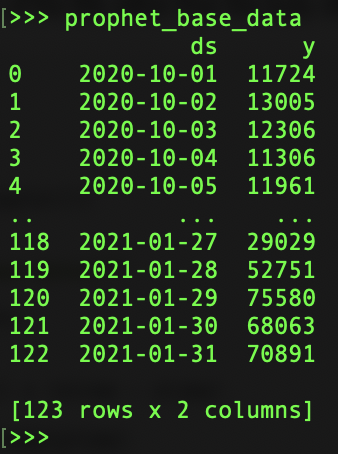
모든 국가 분석에서 특정 KPI 유형에 대한 샘플 데이터는 다음과 같습니다. Prophet 모듈을 데이터에 적용하기 전에 컬럼 이름을 'ds'(날짜 변수)와 'y'(대상 변수)로 정렬해야 합니다.
첫 번째 코드 스니펫에서는 데이터를 모델링하는 fit_predict_model 메서드를 검토할 수 있습니다 . 두 번째 방법은 detect_outliers라는 변칙점을 판별하는 방법이 있습니다. 샘플 코드 조각이기 때문에 메서드 매개 변수의 기본값을 사용했습니다. Prophet() 함수 에서 매개변수(yearly_seasonality, daily_seasonality,seasonality_prior_scale 등)를 변경하여 보다 강력한 모델을 만들 수 있습니다 .
def fit_predict_model(df, metric_type, country):
"""
:param df: dataframe
:param metric_type: string
:param country: string
:rtype: dataframe
"""
try:
# define the model
m = Prophet()
# fit the model
m = m.fit(df)
# use the model to find an outlier
forecast = m.predict(df)
forecast['actual'] = df['y'].reset_index(drop=True)
# displaying Prophet plot
fig1 = m.plot(forecast)
return forecast
except Exception as e:
logger.error(e.args)
mess = "Model could not be fitted for {0}_{1}! There can be improper model data.".format(metric_type, country)
logger.error(mess)
send_slack_notif_for_fails(mess)
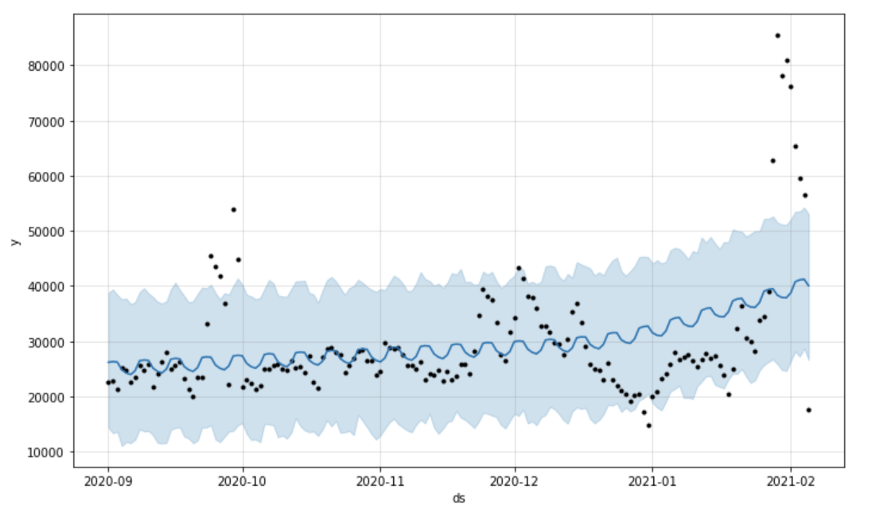
이상 감지 ;
- 위 그래프의 연한 파란색 경계는 yhat_upper 및 yhat_lower입니다.
- y 값이 yhat_upper보다 크고 yhat_lower보다 작으면 비정상입니다.
def detect_outliers(forecast):
"""
:param forecast: dataframe
:rtype: dataframe
"""
forecasted = forecast[['ds', 'trend', 'yhat', 'yhat_lower', 'yhat_upper', 'actual']].copy()
logger.info("Creating anomaly status...")
forecasted['anomaly'] = 0
forecasted.loc[forecasted['actual'] > forecasted['yhat_upper'], 'anomaly'] = 1
forecasted.loc[forecasted['actual'] < forecasted['yhat_lower'], 'anomaly'] = -1
# Anomaly score or importance can be created by using below formulas.
# high = (actual - yhat_upper) / actual
# low = (yhat_lower - actual) / actual
return forecasted
프로젝트 구조 및 데이터 시각화
이상점을 탐지한 후 데이터 과학 영역에서 마지막으로 중요한 단계인 시각화가 남아 있습니다. 우리는 항상 최신 BI 도구를 사용하여 프로젝트 결과에 대한 의미 있는 이야기를 만들어야 합니다. 저는 개발에서 외부 도구 대신 최근 몇 년 동안 인기 있는 패키지인 Plotly를 사용했습니다. 나는 생산을 위해 Grafana를 선택했습니다. 또한 프로덕션에서 감지된 이상 징후에 대한 slack의 도움으로 경고 메커니즘을 만들었습니다. 이 구조를 선호하지 않는 사람들은 Grafana 내에서 경고 메커니즘을 만들 수도 있습니다. 아래에서 다이어그램을 통해 프로젝트의 구조를 확인할 수 있습니다. 데이터 애호가 친구를 위해 개발 부분을 예시하여 종단 간 데이터 과학 프로젝트가 비즈니스에 어떻게 제시되어야 하는지 보여주고 싶었습니다.
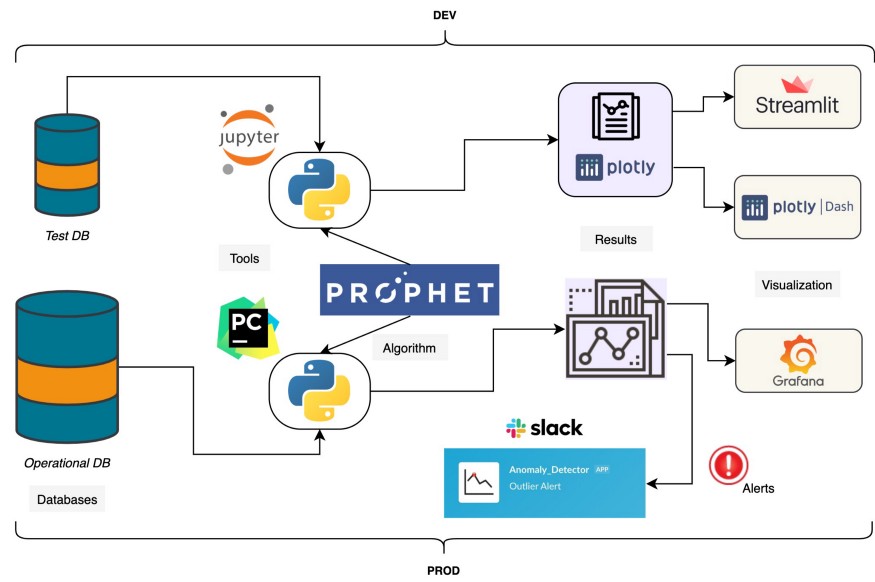
배포 및 모니터링
배포 단계는 모든 기계 학습 프로젝트의 핵심 영역입니다. 최대한 자동화된 구조를 구축해야 합니다. 배포 단계를 용이하게 할 수 있는 많은 도구가 있습니다. Bitbucket 을 사용 하여 이상 감지 프로젝트를 저장, 구축, 테스트 및 배포했습니다. 배포 프로세스를 관리한 Beytullah Gürpınar 에게 감사드립니다 . 배포 단계에 대한 자세한 내용은 다른 기사에서 다루겠습니다. Docker 부분에 대해 간단히 이야기하겠습니다. 샘플 프로젝트 구조는 아래와 같습니다.
workspace
├── project
│ ├── anomaly-detection (repository)
│ ├── .gitignore
│ ├── anomaly_detector.py
│ ├── bitbucket-pipelines.yml
│ ├── build_docker_image.sh
│ ├── Dockerfile
│ ├── ml_anomaly_detector_docker_image_version
│ ├── push_docker_image_to_gcr.sh
│ ├── README.md
│ ├── requirements.txt
│ ├── settings.yaml
│ ├── settings_dev.yaml
ML 개발 및 ML 애플리케이션 배포에 도커를 사용했습니다. 먼저 프로젝트에 아래 Dockerfile을 사용했습니다.
FROM python:3.7
COPY . /app
RUN pip install Cython numpy pandas
RUN pip install pystan
RUN pip install -r /app/requirements.txt
RUN chmod 755 /app/anomaly_detector.py
ENTRYPOINT ["python"]
CMD ["/app/anomaly_detector.py"]
'requirements.txt' 파일에는 다음 패키지가 포함되어 있습니다.
requests
SQLAlchemy
mysql-connector-python
mysqlclient
fbprophet
pyyaml
그러나 배포 시 Docker의 Prophet용 pip에서 몇 가지 컴파일 문제가 발생했습니다. 문제는 conda를 사용하여 극복되었습니다.
FROM continuumio/miniconda3
COPY . /app
RUN pip3 install mysql-connector-python
RUN conda install -c conda-forge pystan
RUN conda install -c conda-forge fbprophet
RUN conda install -c anaconda cython
RUN conda install -c anaconda numpy
RUN conda install -c anaconda PyMySQL
RUN conda install -c anaconda pandas
RUN conda install -c anaconda requests
RUN conda install -c anaconda sqlalchemy
RUN conda install -c bioconda mysqlclient
RUN conda install -c anaconda pyyaml
RUN chmod 755 /app/anomaly_detector.py
ENTRYPOINT ["python3"]
CMD ["/app/anomaly_detector.py"]
패키지를 하나씩 작성하는 대신 단일 명령으로 또는 yml 파일 을 사용하여 패키지를 설치할 수 있습니다 .
결론

일부 국가에서 필수 KPI를 모니터링하기 위한 이상 탐지 프로젝트가 수행되었습니다. 이런 식으로 기계 학습 알고리즘을 사용하여 어떤 KPI가 어떤 국가에서 경고했는지 알 수 있습니다. 유용한 python 라이브러리가 몇 개 적용되었고, dev & prod 환경을 명확히 하여 end-to-end 머신러닝 프로젝트를 자세히 고려했습니다.
안전 유지. Getcontact와 함께하세요!
'Daily Review' 카테고리의 다른 글
| 데이터 사이언티스트가 꼭 알아야 하는 '통계적 가설 검증법' 1가지. (0) | 2022.08.31 |
|---|---|
| 스파게티 차트(Spaghetti Charts) 대신 제안된 대안: 격자 차트(Trellis Chart) (0) | 2022.08.31 |
| SQL을 사용한 레스토랑 판매의 탐색적 데이터 분석(EDA) (3) | 2022.08.30 |
| 머신 러닝을 위한 데이터 전처리 (0) | 2022.08.30 |
| 데이터 분석가로서 알아야 할 7가지 SQL 쿼리 (0) | 2022.08.29 |




댓글