T1, T2, P1, F1 및 Power가 있으며 작동이 정상일 때 변수가 특정 범위를 갖는다고 가정합니다.
시스템에 이상이 있는 경우 이러한 매개변수는 비정상적인 동작을 따릅니다.
따라서 간단히 말해서 데이터에서 이러한 숨겨진 비정상적인 동작을 찾는 것이 Anomaly detection” 문제입니다.
pyod 라는 별도의 패키지에 구현된 많은 알고리즘이 있습니다 .
그러나 이 기사에서는 다변량 가우스 분포 알고리즘에 대해 설명합니다.
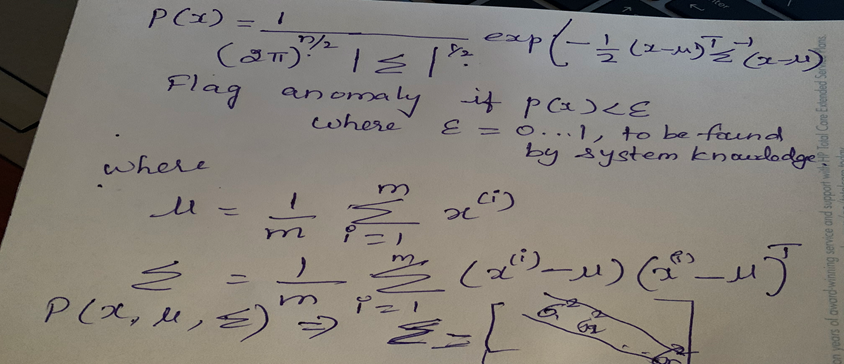
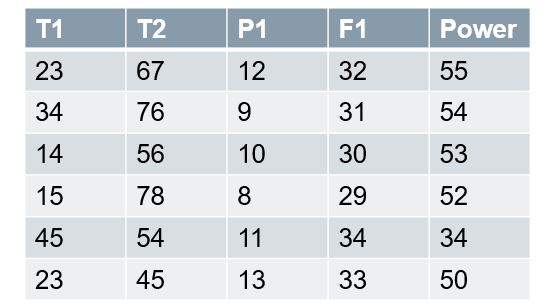
수식에 대한 내 손글씨 노트 — 기계 학습 과정인 Andrew Ng를 참조하십시오.
단계:
- 매개변수가 지정된 값 범위에 속할 확률을 찾습니다.
- 확률이 지정된 한계(도메인에 따라 다름) 이상으로 벗어나면 이상으로 간주됩니다.
일변량 가우스 분포는 단일 매개변수에 대해 표시됩니다.
1보다 크면 다변량 가우스 분포가 표시됩니다. 예를 들어, 다변량 가우스 분포를 온도 대 압력에 대해 플롯하면 아래와 같이 나타납니다.
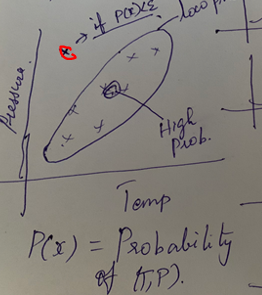
위의 다변량 가우스 분포에서 온도와 압력 사이의 상관관계가 양의 선형임을 알 수 있습니다. 그리고 평균과 표준 편차 범위 내에서 점의 확률을 찾으면 모든 정규 데이터가 원 안에 포함됩니다. 데이터의 확률이 빨간색 원과 같이 임계값을 초과하면 이상으로 간주됩니다.
알고리즘은 평균 및 공분산 행렬을 기반으로 확률을 찾는 작업을 포함하기 때문에 중요한 하이퍼파라미터가 없습니다.
그러나 데이터가 "변칙"으로 식별될 확률에 대한 가장 낮은 임계값은 데이터 및 도메인 지식을 기반으로 조정이 필요합니다.
Multi variate Gaussian Anomaly detection에 대한 가장 좋은 참조는 Andrew Ng Machine Learning 과정에서 사용할 수 있습니다.
'Daily Review' 카테고리의 다른 글
| 단 6개월 만에 데이터 과학자가 되는 방법! (1) | 2022.09.09 |
|---|---|
| PyOD로 이상값 감지 (1) | 2022.09.09 |
| 데이터 초보자가 Excel을 즉시 배워야 하는 10가지 이유 (0) | 2022.09.08 |
| Python에서 루프와 함께 loc/iloc을 사용하지 말고 대신 이것을 사용하십시오! (0) | 2022.09.08 |
| 효과적인 데이터 시각화를 위한 8가지 팁 (0) | 2022.09.08 |




댓글